이제 모델을 학습 했으므로 다음 단계는 웹캠 / 비디오 파일에 액세스하고 각 프레임에 미소 감지를 적용하는 Python 스크립트를 빌드하는 것입니다. 이 단계를 수행하려면 새 파일을 열고 detect_smile.py라는 이름을 지정하면 작업을 시작합니다.
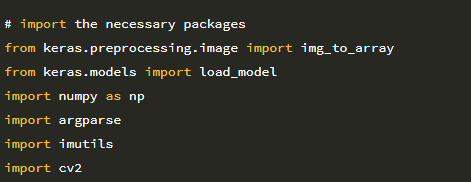
2-7 행은 필수 Python 패키지를 가져옵니다. img_to_array 함수는 비디오 스트림의 각 개별 프레임을 적절한 채널 순서 배열로 변환하는 데 사용됩니다. load_model 함수는 훈련 된 LeNet 모델의 가중치를 디스크에서 로드하는 데 사용됩니다. detectsmile.py 스크립트에는 두 개의 명령 줄 인수와 세 번째 선택적 인수가 필요합니다
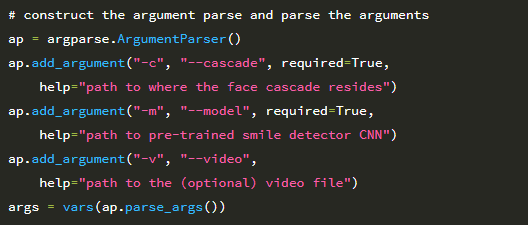
첫 번째 인수 인 –cascade는 이미지에서 얼굴을 감지하는 데 사용되는 Haar 캐스케이드의 경로입니다. Paul Viola와 Michael Jones가 2001 년에 처음 발표한 논문 Rapid Object Detection using a Boosted Cascade of Simple Features 에서 언급되었으며, 이 출판물은 컴퓨터 비전 문헌에서 가장 많이 인용되는 논문 중 하나가되었습니다.
Haar 캐스케이드 알고리즘은 위치와 크기에 관계없이 이미지에서 물체를 감지 할 수 있습니다. 아마도 가장 흥미롭고 (그리고 우리 애플리케이션과 관련이있는) 감지기는 최신 하드웨어에서 실시간으로 실행될 수 있습니다. 실제로 Viola와 Jones의 작업 뒤에있는 동기는 얼굴 감지기를 만드는 것이 었습니다. 기존의 컴퓨터 비전 방법을 사용한 물체 감지에 대한 자세한 검토는 이 책의 범위를 벗어나므로 객체 감지를위한 일반적인 Histogram of Oriented Gradients + Linear SVM 프레임 워크와 함께 Haar 캐스케이드를 검토해야합니다.
두 번째 공통 라인 인수 –model은 디스크에서 직렬화 된 LeNet 가중치에 대한 경로를 지정합니다. 스크립트는 기본적으로 USB 웹캠에서 프레임을 읽는 것입니다. 그러나 대신 파일에서 프레임을 읽으려면 선택적 –video 스위치를 통해 파일을 지정할 수 있습니다.
웃는 얼굴 감지하기 전에 먼저 몇 가지 초기화를 수행해야합니다.

20과 21행은 각각 Haar 캐스케이드 얼굴 감지기와 사전 훈련된 LeNet 모델을 로드합니다. 비디오 경로가 제공되지 않은 경우 웹캠에 대한 포인터를 가져옵니다 (24 및 25 행). 그렇지 않으면 디스크의 비디오 파일에 대한 포인터를 엽니 다 (28 및 29 행).
이제 애플리케이션의 주요 처리 파이프 라인 입니다.
32 행은 (1) 스크립트를 중지하거나 (2) 비디오 파일의 끝에 도달 할 때까지 계속되는 루프를 시작합니다 (–video 경로가 적용된 경우).
34 행은 비디오 스트림에서 다음 프레임을 가져옵니다. 프레임을 잡을 수 없다면 비디오 파일의 끝에 도달 한 것입니다. 그렇지 않으면 300 픽셀 너비가 되도록 프레임 크기를 조정 (43 행)하고 그레이 스케일로 변환 (44 행)하여 얼굴 감지를 위해 프레임을 전처리합니다.
.detectMultiScale 메서드는 프레임에있는 면의 경계 상자 (x, y) 좌표 감지를 처리합니다.
여기에서 회색조 이미지를 전달하고 주어진 영역이 얼굴로 간주 되려면 최소 너비가 30×30 픽셀이어야 함을 나타냅니다. minNeighbors 속성은 거짓양성 값을 제거하는 데 도움이 되며 scaleFactor는 생성 된 이미지 피라미드 수를 제어합니다.
.detectMultiScale 메서드는 프레임에서 얼굴을 경계하는 사각형을 구성하는 4 개의 튜플 목록을 반환합니다. 이 목록의 처음 두 값은 시작 (x, y) 좌표입니다. rects list 두 번째 두 값은 각각 경계 상자(bounding box)의 너비와 높이입니다.
아래에서 각 bounding box 세트를 반복합니다.
각 경계 상자에 대해 NumPy 어레이 슬라이싱을 사용하여 얼굴 ROI를 추출합니다 (58 행).
ROI가 확보되면 크기를 조정하고, 크기를 조정하고, Keras와 호환되는 배열로 변환하고, 이미지를 추가 차원으로 채움 (59-62 행)으로써 LeNet을 통해 분류를 준비합니다.
ROI가 사전 처리되면 분류를 위해 LeNet을 통과 할 수 있습니다.
66 번 줄에서 .predict를 호출하면 각각 “not smiling”및 “smiling”확률이 반환됩니다. 67 행은 어떤 확률이 더 큰지에 따라 레이블을 설정합니다. 레이블이 있으면 프레임의 해당 경계 상자와 함께 레이블을 그릴 수 있습니다
마지막 코드 블록은 출력 프레임을 화면에 표시하는 작업을 처리합니다.
q 키를 누르면 스크립트를 종료합니다. 웹캠을 사용하여 detect_smile.py를 실행하려면 다음 명령을 실행하십시오.
대신 비디오 파일을 사용하려면 –video 스위치를 사용하도록 명령을 업데이트합니다.
아래 그림에 미소 감지 스크립트의 결과를 포함했습니다.
LeNet이 내 표정을 기반으로 “미소”또는 “미소”를 올바르게 예측하는 방법을 확인하십시오.
이 장에서는 미소 감지를 수행하기 위해 종단 간 컴퓨터 비전 및 딥 러닝 애플리케이션을 구축하는 방법을 배웠습니다. 이를 위해 먼저 SMILES 데이터 세트에서 LeNet 아키텍처를 훈련했습니다.
SMILES 데이터 세트의 클래스 불균형으로 인해 문제를 완화하는 데 사용되는 클래스 가중치를 계산하는 방법을 발견했습니다.
훈련을 마친 후 테스트 세트에서 LeNet을 평가 한 결과 네트워크가 93 %의 뛰어난 분류 정확도를 얻었습니다. 더 많은 훈련 데이터를 수집하거나 기존 훈련 데이터에 데이터 증가를 적용하면 더 높은 분류 정확도를 얻을 수 있습니다.
그런 다음 웹캠 / 비디오 파일에서 프레임을 읽고 얼굴을 감지 한 다음 사전 훈련 된 네트워크를 적용하는 Python 스크립트를 만들었습니다. 얼굴을 감지하기 위해 OpenCV의 Haar 캐스케이드를 사용했습니다. 얼굴이 감지되면 프레임에서 추출한 다음 LeNet을 통해 사람이 웃고 있는지 여부를 확인했습니다. 전반적으로 우리의 미소 감지 시스템은 최신 하드웨어를 사용하여 CPU에서 실시간으로 쉽게 실행할 수 있습니다.