이 장에서는 전통적인 컴퓨터 비전 기술과 함께 딥 러닝을 사용하여 실시간으로 비디오 스트림에서 미소를 감지 할 수있는 완전한 end-to-end 애플리케이션을 구축 할 것입니다. 이 작업을 수행하기 위해 웃고, 있지 않은 사람들의 얼굴이 포함 된 이미지 데이터 세트에서 LetNet 아키텍처를 교육합니다. 네트워크가 훈련되면 별도의 Python 스크립트를 생성합니다.
이 스크립트는 OpenCV의 내장 Haar 캐스케이드 얼굴 감지기를 통해 이미지에서 얼굴을 감지하고 이미지에서 관심 영역 (ROI)을 추출한 다음 ROI를 미소 감지를 위해 LeNet을 통해 전달합니다.
이미지 분류를위한 실제 애플리케이션을 개발할 때 종종 기존의 컴퓨터 비전과 이미지 처리 기술을 딥 러닝과 혼합해야합니다. OpenCV 및 기타 컴퓨터 비전 기술에 대한 전체 검토는이 책의 범위를 벗어납니다. OpenCV 및 이미지 처리 기본 사항에 익숙해 지려면 OpenCV 다른 책을 읽어 보는 것이 좋습니다.
컴퓨터 비전 및 이미지 처리의 배경에 관계 없이 이 장을 마치면 자신의 응용 프로그램에서 사용할 수있는 완전한 미소 감지 솔루션을 사용합니다.
SMILES 데이터 세트는 웃거나 웃지 않는 얼굴의 이미지로 구성됩니다. 총 13,165 개의 그레이 스케일 이미지가 데이터 세트에 있으며 각 이미지의 크기는 64×64 픽셀입니다. 아래 그림에서 알 수 있듯이,이 데이터 세트의 이미지는 얼굴 주변에서 잘려서 입력 이미지에서 직접 “smiling”또는 “not smiling”패턴을 배울 수 있으므로 훈련 과정이 더 쉬워집니다. 이 책 앞부분의 유사한 작업을 했었던과 같습니다.

위 : “웃는”얼굴의 예. 아래 : “웃지 않는”얼굴 샘플. 이 장에서는 실시간 비디오 스트림에서 웃는 얼굴과 웃는 얼굴이 아닌 얼굴을 인식하는 컨볼 루션 신경망을 훈련 할 것입니다.
그러나 근접해 자르기는 테스트 중에 문제가됩니다. 입력 이미지에는 얼굴뿐만 아니라 이미지의 배경도 포함되므로 먼저 이미지에서 얼굴을 로컬라이즈 하기 전에 얼굴 ROI를 추출해야합니다. 운 좋게도 Haar cascades와 같은 전통적인 컴퓨터 비전 방법을 사용하면 생각보다 훨씬 쉬운 작업입니다.
SMILES 데이터 세트에서 처리해야하는 두 번째 문제는 클래스 불균형입니다. 데이터 세트에 13,165 개의 이미지가 있지만 이 예제 중 9,475 개는 not smiling이고 3,690 개만 smiling 클래스에 속합니다. “smiling”예제보다 “not smiling” 이미지의 수가 2.5 배 이상이라는 점을 감안할 때, 우리는 훈련 절차를 고안 할 때 주의해야합니다.
우리의 네트워크는 자연스럽게 “not smiling”레이블을 선택할 수 있습니다. 왜냐하면 (1) 분포가 고르지 않고 (2) “not smiling” 얼굴이 어떻게 생겼는지에 대한 더 많은 예가 있기 때문입니다.이 장의 뒷 부분에서 훈련 시간 동안 각 클래스의 “weight”를 계산하여 클래스 불균형을 해결할 수 있습니다.
데이터셋 위치 : https://github.com/hromi/SMILEsmileDhromi/SMILEsmileDopen source smile detector haarcascade and associated positive & negative image datasets – hromi/SMILEsmileDgithub.com
미소 감지기를 구축하는 첫 번째 단계는 SMILES 데이터 세트에서 CNN을 훈련하여 미소 짓는 얼굴과 미소 짓지 않는 얼굴을 구분하는 것입니다. 이 작업을 수행하기 위해 train_model.py라는 새 파일을 만들어 보겠습니다. 다음 코드를 삽입하십시오.
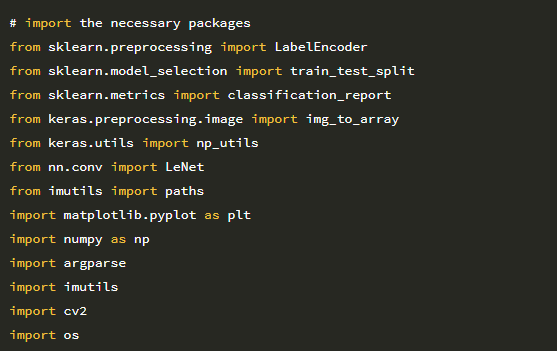
2 ~ 14 행은 필수 Python 패키지를 가져옵니다. 이전에 모든 패키지를 사용했지만 LeNet (14 장) 클래스를 가져 오는 7행 에 주의 하십시오. 이것이 스마일 감지기를 만들 때 사용할 아키텍처입니다. 다음으로 명령 줄 인수를 구문 분석해 보겠습니다.
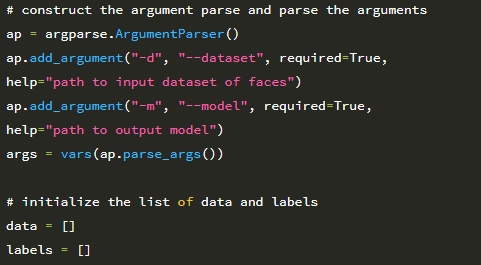
스크립트에는 두 개의 명령 줄 인수가 필요하며, 각 인수는 아래에서 자세히 설명합니다.
1. –dataset : 디스크에있는 SMILES 디렉토리의 경로입니다.
2. –model : 훈련 후 직렬화 된 LeNet 가중치가 저장되는 경로입니다. 이제 디스크에서 SMILES 데이터 세트를 로드하여 메모리에 저장할 준비가되었습니다.
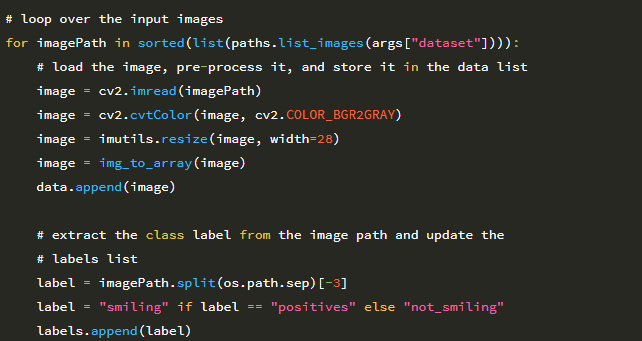
29 행에서는 –dataset 입력 디렉토리의 모든 이미지를 반복합니다. 이러한 각 이미지에 대해 다음을 수행합니다.
1. 디스크에서 로드합니다 (31 행).
2. 그레이 스케일로 변환합니다 (32 행).
3. 고정 입력 크기가 28 × 28 픽셀 (33 행)이 되도록 크기를 조정합니다.
4. 이미지를 Keras 및 채널 순서와 호환되는 배열로 변환합니다 (34 행).
5. LeNet이 학습 할 데이터 목록에 이미지를 추가합니다.
39-41 행은 imagePath에서 클래스 레이블을 추출하고 레이블 목록을 업데이트합니다. SMILES 데이터 세트는 웃는 얼굴을 SMILES / positives / positives7 하위 디렉토리에 저장하고 웃는 얼굴이 아닌 경우 SMILES / negatives / negatives7 하위 디렉토리에 있습니다.
따라서 이미지 경로를 보면 :
이미지 경로 구분자를 분할하고 마지막에서 세 번째 하위 디렉토리 인 positives를 잡아서 클래스 레이블을 추출 할 수 있습니다. 이 역할은 39행이 수행합니다.
이제 데이터와 레이블이 구성되었으므로 원시 픽셀 강도를 [0,1] 범위로 확장 한 다음 레이블에 원-핫 인코딩을 적용 할 수 있습니다

다음 코드 블록은 클래스 가중치를 계산하여 데이터 불균형 문제를 처리합니다.

52 행은 클래스 당 총 예제 수를 계산합니다. 이 경우 classTotals는 각각 “not smiling”및 “smiling”에 대한 [9475, 3690] array가 됩니다. 그런 다음 53 행에서 이 합계를 조정하여 클래스 불균형을 처리하는 데 사용되는 classWeight를 구하여 [1, 2.56] 배열을 생성합니다. 이 가중치는 우리 네트워크가 모든 “smiling” 인스턴스를 2.56 개의 “not smiling”인스턴스로 취급하고 “smiling” 예제를 볼 때 인스턴스 당 손실을 더 큰 가중치로 확대하여 클래스 불균형 문제를 해결하는 데 도움이 된다는 것을 의미합니다.
클래스 가중치를 계산 했으므로 이제 데이터의 80 %를 학습에 사용하고 20 %를 테스트에 사용하여 데이터를 학습 및 테스트 분할로 분할 할 수 있습니다.

이제 LeNet으로 학습합니다.
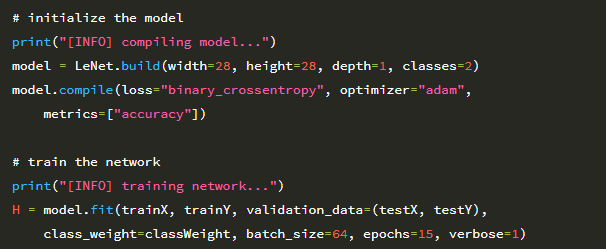
62행은 28 × 28 단일 채널 이미지를 수용하는 LeNet 아키텍처를 초기화합니다. 두 개의 클래스 (smiling 또는 not smiling)만 있다는 점을 감안할 때 classes = 2를 설정합니다.
또한 손실 함수로 categorical_crossentropy 대신 binary_crossentropy를 사용할 것입니다. 다시 말하지만 범주형 교차 엔트로피는 클래스 수가 2 개 이상일 때만 사용됩니다.
지금까지 우리는 네트워크를 훈련하기 위해 SGD 최적화 프로그램을 사용해 왔습니다. 여기서는 Adam (63 행)을 사용합니다. 더 진보 된 옵티 마이저 (Adam, RMSprop, Adadelta 포함)는 나중에 다룹니다. 그러나 이 예제에서는 Adam이 특정 상황에서 SGD보다 빠르게 수렴 할 수 있다는 것만 이해하면 됩니다.
다시 말하지만, 옵티마이저 및 관련 매개 변수는 종종 네트워크를 훈련 할 때 조정해야 하는 초 매개 변수로 간주됩니다. 이 예제를 종합했을 때 Adam이 SGD보다 훨씬 더 나은 성과를 냈다는 것을 알게 되었습니다. 68과 69행은 클래스 불균형에 맞서기 위해 제공된 classWeight를 사용하여 총 15 epoch 동안 LeNet을 훈련시킵니다.
네트워크가 훈련되면 이를 평가하고 가중치를 디스크에 직렬화 할 수 있습니다.

또한 성능을 시각화 할 수 있도록 네트워크에 대한 학습 곡선을 구성 할 것입니다.

스마일 감지기를 훈련 시키려면 다음 명령을 실행하십시오.
15 epoch 후에 네트워크가 93 %의 분류 정확도를 얻고 있음을 알 수 있습니다. 아래 그림은 학습 곡선을 나타냅니다.
6 epoch 이후의 validation loss가 정체되기 시작합니다. 15 epoch 이후의 추가 훈련은 과적합을 초래합니다. 원하는 경우 다음과 같은 방법으로 더 많은 훈련 데이터를 사용하여 미소 감지기의 정확도를 향상시킬 수 있습니다.
1. 추가 훈련 데이터 수집.
2. 데이터 증가를 적용하여 기존 훈련 세트를 무작위로 변환, 회전 및 이동합니다. 데이터 증대는 나중에 자세히 다룹니다.