이 섹션의 첫 번째 부분에서는 매우 작은 데이터 세트 인 Flowers-17 데이터 세트 (컴퓨터 비전 작업을위한 딥러닝 측면에서)에 대해 설명하고 데이터 증가가 이 데이터 세트의 크기를 추가 교육 샘플이 어떻게 도움이 되는지 여기에서 두 가지 실험을 수행합니다.
1. 데이터 augmentation없이 Flowers-17에서 MiniVGGNet을 훈련시킵니다.
2. 데이터 augmentation을 사용하여 Flowers-17에서 MiniVGGNet을 훈련시킵니다.
곧 알게 되겠지만 데이터 증대를 적용하면 과적합이 크게 줄어들고 MiniVGGNet이 훨씬 더 높은 분류 정확도를 얻을 수 있습니다.
22.3.1 Flowers-17 데이터 세트
Flowers-17 데이터 세트 [10]는 17 개의 서로 다른 꽃 종을 인식하는 세분화 된 분류 과제입니다. 이미지 데이터 세트는 매우 작으며 총 1,360 개의 이미지에 대해 클래스 당 80 개의 이미지 만 있습니다. 컴퓨터 비전 작업에 딥러닝을 적용 할 때 일반적인 경험 법칙은 수업 당 1,000 ~ 5,000 개의 예제를 포함하는 것이므로 여기서는 확실히 부족합니다. 모든 범주가 매우 유사하기 때문에 Flowers-17을 fined-graied 분류작업이라고 부릅니다 (예 : 꽃 종).

각 클래스가 특정 꽃 종을 나타내는 Flowers-17 데이터 세트의 5 개 (총 17 개 중) 클래스 샘플.
사실 우리는 이러한 각 범주를 하위 범주로 생각할 수 있습니다. 카테고리는 확실히 다르지만 상당한 양의 공통 구조를 공유합니다.(꽃잎, 수술, 암술 등) fine-grained 분류 작업은 기계 학습 모델이 매우 유사한 클래스를 구별하기 위해 극도로 구별되는 기능을 학습해야 함을 의미하므로 딥러닝 실무자에게 가장 어려운 경향이 있습니다. 이 세분화 된 분류 작업은 제한된 훈련 데이터를 고려할 때 훨씬 더 문제가됩니다.
Flowers-17 데이터 다운로드$ curl -LO http://www.robots.ox.ac.uk/~vgg/data/flowers/17/17flowers.tgz $ tar -xzf 17flowers.tgz
이제 모든 이미지가 jpg라는 폴더에 있습니다. 이러한 이미지를 flower_dataset / train 및 flower_dataset / test 디렉토리로 분할합니다. 각 디렉토리에는 split.py를 사용하여 17 개의 꽃 클래스에 해당하는 하위 디렉토리가 포함되어 있습니다.
split.py 파일을 실행합니다. train 디렉토리에는 각 클래스에 대해 70 개의 이미지가 포함되고 test 디렉토리에는 각 클래스에 대해 10 개의 이미지가 포함됩니다.
지금까지는 영상 비를 무시하고 고정 된 크기로 크기를 조정하여 이미지 만 전처리했습니다. 일부 상황에서, 특히 기본 벤치마크 데이터 세트의 경우 그렇게하는 것이 허용됩니다. 그러나 더 까다로운 데이터 세트의 경우 고정 된 크기로 크기를 조정하되 종횡비를 유지해야합니다. 이 동작을 시각화하려면 아래 그림을 보십시오
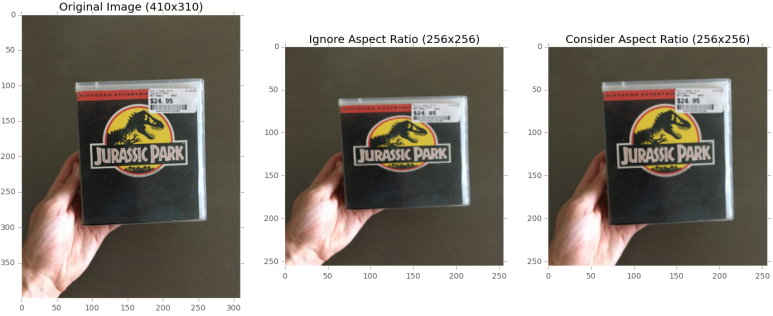
왼쪽 : 원본 입력 이미지 (410 × 310).
중간 : 화면 비율을 무시하고 이미지 크기를 256×256 픽셀로 조정합니다. 이제 이미지가 찌그러지고 왜곡 된 것처럼 보입니다.
오른쪽 : 가로 세로 비율을 유지하면서 이미지 크기를 256 × 256으로 조정합니다.
왼쪽에는 고정 된 너비와 높이로 크기를 조정해야하는 입력 이미지가 있습니다. 가로 세로 비율을 무시하고 이미지 크기를 256 × 256 픽셀 (가운데)로 조정하여 원하는 크기에 맞도록 효과적으로 이미지를 찌그러 뜨리고 왜곡합니다. 더 나은 접근 방식은 이미지의 종횡비 (오른쪽)를 고려하는 것입니다. 먼저 너비가 256 픽셀이되도록 더 짧은 치수를 따라 크기를 조정 한 다음 높이를 따라 이미지를 자르고 높이가 256 픽셀이 되도록합니다. 자르는 동안 이미지의 일부를 효과적으로 버렸지 만 이미지의 원래 종횡비도 유지했습니다. 일관된 종횡비를 유지하면 Convolutional Neural Network가보다 차별적이고 일관된 기능을 학습 할 수 있습니다. aspect-aware 전처리가 어떻게 구현되는지 확인하기 위해 AspectAwarePreprocessor를 포함하도록 프로젝트 구조를 업데이트 해 보겠습니다.

전처리 하위 모듈 내에 aspectawarepreprocessor.py라는 새 파일을 추가 한 방법에 주목하십시오. 이 위치는 새 전처리기가 있을 위치입니다. aspectawarepreprocessor.py를 열고 다음 코드를 삽입하십시오

SimplePreprocessor에서와 마찬가지로 생성자는 이미지 크기를 조정할 때 사용되는 보간 방법과 함께 두 개의 매개 변수 (대상 출력 이미지의 원하는 너비 및 높이)가 필요합니다. 그런 다음 아래에서 전처리 기능을 정의 할 수 있습니다.
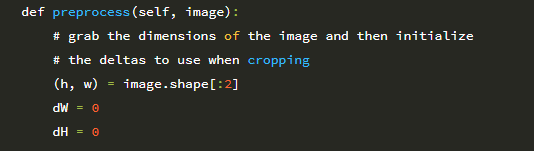
전처리 함수는 전처리하려는 이미지인 단일 인수를받습니다.
16 행은 입력 이미지의 너비와 높이를 잡고, 17 행과 18 행은 더 큰 치수를 따라 자를 때 사용할 델타 오프셋을 결정합니다. 다시 말하지만, 비율 인식 전처리 기는 2 단계 알고리즘입니다.
1. 단계 # 1 : 가장 짧은 치수를 결정하고 그에 따라 크기를 조정합니다.
2. 단계 # 2 : 목표 너비와 높이를 얻기 위해 가장 큰 치수를 따라 이미지를 자릅니다.
다음 코드 블록은 너비가 높이보다 작은 지 확인하고, 그렇다면 너비를 따라 크기를 조정합니다.

그렇지 않고 높이가 너비보다 작으면 높이를 따라 크기를 조정합니다.
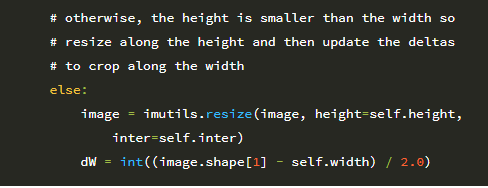
이제 이미지의 크기가 조정되었으므로 너비와 높이를 다시 잡고 델타를 사용하여 이미지 중앙을 잘라야합니다.

잘라낼 때 (반올림 오류로 인해) 이미지 대상 이미지 크기가 ± 1 픽셀만큼 벗어날 수 있습니다. 따라서 출력 이미지가 원하는 너비와 높이를 갖도록 cv2.resize를 호출합니다. 그런 다음 전처리 된 이미지가 호출 함수로 반환됩니다. AspectAwarePreprocessor를 구현 했으므로 이제 Flowers-17 데이터 세트에서 MiniVGGNet 아키텍처를 학습 할 때 작동하도록 하겠습니다.