rank-1 및 rank-5 정확도는 간단한 유틸리티 함수를 구축하여 계산할 수 있습니다. 모듈 내에서 rank.py라는 파일을 추가하여 이 기능을 utils 하위 모듈에 추가합니다.

rank.py를 열고 rank5_accuracy 함수를 정의합니다.
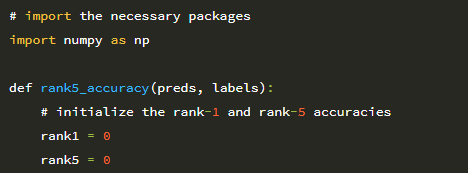
4 행은 rank5_accuracy 함수를 정의합니다. 이 방법은 다음 두 가지 매개 변수를 받습니다.
• preds : N × T 행렬, 행 수 N은 각 클래스 레이블 T와 관련된 확률을 포함합니다.
• labels : 데이터 세트의 이미지에 대한 정답 레이블.
그런 다음 6 행과 7 행에서 각각 rank-1 및 rank-5 정확도를 초기화합니다. 계속해서 rank-1 및 rank-5 정확도를 계산해 보겠습니다.
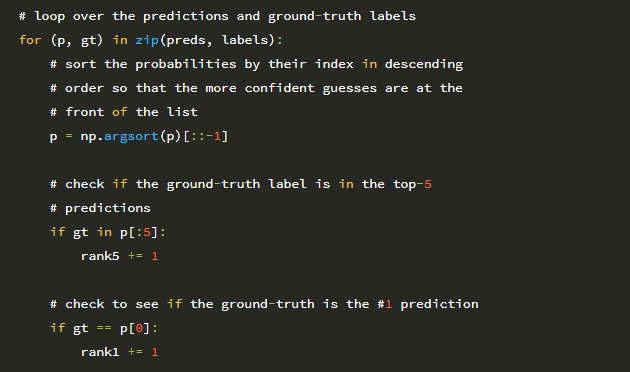
10 행에서 데이터 세트의 각 예에 대한 예측 및 정답 클래스 레이블을 반복하기 시작합니다. 14 행은 예측 확률 p를 내림차순으로 정렬하여 가장 큰 확률의 인덱스가 목록의 맨 앞에 배치되도록합니다. 정답 레이블이 상위 5 개 예측에 존재하는 경우 rank-5 변수를 증가시킵니다 (18 행 및 19 행). 정답 레이블이 1 위 위치와 같으면 rank-1 변수를 증가시킵니다 (22 행 및 23 행).
마지막 코드 블록은 총 레이블 수로 나누어 rank-1과 rank-5를 백분율로 변환합니다.
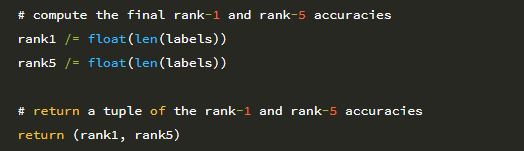
30 행은 rank-1 및 rank-5 정확도의 2-튜플을 호출 함수에 반환합니다.
데이터 세트의 rank-1 및 rank-5 정확도를 계산하는 방법을 보여주기 위해 23 장으로 돌아가서 ImageNet 데이터 세트에서 사전 훈련 된 컨볼루션 신경망을 특징 추출기로 사용했습니다. 이러한 추출 된 기능을 기반으로 데이터에 대한 로지스틱 회귀 분류기를 훈련하고 모델을 평가했습니다. 이제 정확도 보고서를 확장하여 rank-5 정확도도 포함합니다.
로지스틱 회귀 모델에 대한 rank-1 및 rank-5 정확도를 계산하는 방식은 모든 머신 러닝, 신경망 또는 딥 러닝 모델에 대해 rank-1 및 rank-5 정확도를 계산할 수 있습니다. 딥러닝 커뮤니티 외부에서 이 두 가지 측정 항목을 모두 실행합니다. 말한대로 새 파일을 열고 이름을 rank_accuracy.py로 지정한 후 다음 코드를 삽입하십시오.
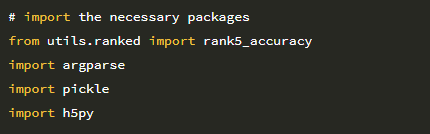
2 ~ 5 행은 필수 Python 패키지를 가져옵니다. 새로 정의 된 rank5_accuracy 함수를 사용하여 각각 예측의 rank-1 및 rank-5 정확도를 계산합니다. pickle 패키지는 디스크에서 사전 훈련 된 scikit-learn 분류기를로드하는 데 사용됩니다. 마지막으로 h5py는 23 장의 CNN에서 추출한 기능의 HDF5 데이터베이스와 인터페이스하는 데 사용됩니다. 다음 단계는 명령 줄 인수를 구문 분석하는 것입니다
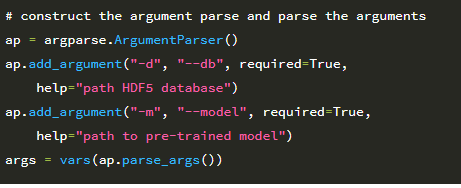
스크립트에는 추출 된 피처의 HDF5 데이터베이스에 대한 경로 인 –db, 사전 훈련 된 로지스틱 회귀 분류기의 경로 인 –model 이 필요합니다. 다음 코드 블록은 데이터의 75 %가 학습에 사용되고 25 %가 테스트에 사용되었다고 가정 할 때 디스크에서 사전 학습 된 모델을 로드하고 HDF5 데이터 세트로 분할 된 학습 및 테스트의 인덱스를 결정합니다.
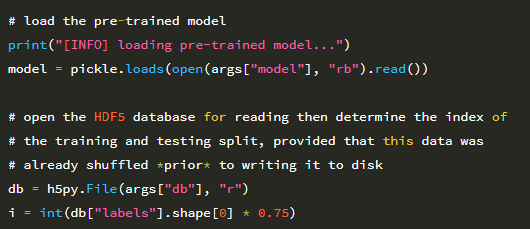
마지막으로 rank-1 및 rank-5 정확도를 계산해 보겠습니다
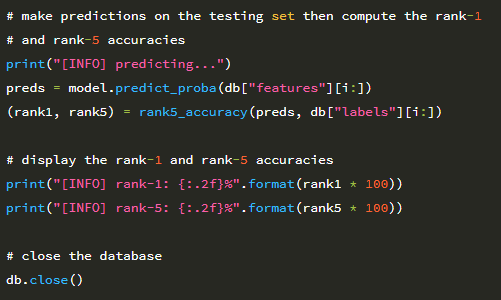
28 행은 테스트 세트의 모든 데이터 포인트에 대한 각 클래스 레이블의 확률을 계산합니다. 예측 된 확률과 테스트 데이터의 정답 레이블을 기반으로 29 행의 순위 정확도를 계산할 수 있습니다.
32 행과 33 행은 각각 rank-1과 rank-5를 터미널에 표시합니다. CNN에서 피처을 추출한 다음 피처 위에 scikit-learn 모델을 훈련시킨 23 장의 모든 예제에서 작동하도록 이 예제를 코딩했습니다.
Flowers-17 데이터 세트에 대한 rank-1 및 rank-5 정확도를 계산해 보겠습니다.

Flowers-17 데이터 세트에서 VGG16 아키텍처에서 추출 된 기능에 대해 훈련 된 로지스틱 회귀 분류기를 사용하여 92.06 % rank-1 정확도를 얻습니다. rank-5 정확도를 살펴보면 분류 기가 거의 완벽하여 99.41 %의 rank-5 정확도를 얻었습니다.

24.1.4 CALTECH-101 Rank 정확도
더 큰 CALTECH-101 데이터 세트에 대한 또 다른 예를 시도해 보겠습니다.

여기서 우리는 95.58 % rank-1 정확도와 99.45 % rank-5 정확도를 얻었으며, 이는 60 % 분류 정확도를 깨기 위해 고군분투했던 이전 컴퓨터 비전 및 머신 러닝 기술보다 크게 향상되었습니다.

24.2 요약
이 장에서는 rank-1 및 rank-5 정확도의 개념을 검토했습니다. rank-1 정확도는 우리의 실측 레이블이 가장 큰 확률로 클래스 레이블과 동일한 횟수입니다. rank-5 정확도는 rank-1 정확도에서 확장되어 좀 더 “관대 한” 순위 입니다. 여기서 우리는 ground-truth 레이블이 가장 큰 확률 상위 5 개 예측 클래스 레이블에 나타나는 횟수에 따라 rank-5 정확도를 계산합니다.
일반적으로 사람 조차도 이미지에 올바르게 레이블을 지정하기 어려운 ImageNet과 같은 크고 까다로운 데이터 세트에 대해 rank-5 정확도를 보고합니다. 이 경우 rank-5 개 예측에 정답 라벨이 단순히 존재하는 경우 모델에 대한 예측이 ‘올바른’ 것으로 간주합니다.
8 장에서 논의했듯이, 진정으로 잘 일반화되는 네트워크는 rank-5 확률에서 상황에 맞는 유사한 예측을 생성합니다.
마지막으로, rank-1 및 rank-5 정확도는 딥러닝 및 이미지 분류에만 국한되지 않습니다. 다른 분류 작업에서도 이러한 메트릭을 볼 수 있습니다.