고급 딥 러닝 주제 (예 : 전이 학습)에 대한 논의가 너무 깊어지기 전에 먼저 한 발 뒤로 물러나서 rank 1, rank -5 및 rank -N 정확도의 개념에 대해 논의하겠습니다. 특히 컴퓨터 비전과 이미지 분류 공간에서 딥 러닝 문헌을 읽을 때 rank 정확도라는 개념을 접하게 될 것입니다. 예를 들어 ImageNet 데이터 세트에서 평가 된 기계 학습 방법을 제시하는 거의 모든 논문은 rank 1 및 rank 5 정확도 측면에서 결과를 제시합니다 (rank-1 및 rank-5 정확도가 보고되는 이유를 알아볼 것입니다).
rank 1 및 rank 5 정확도는 정확히 무엇입니까? 그리고 기존의 정확도 (즉, 정밀도)와 어떻게 다른가요? 이 장에서는 rank 정확도에 대해 논의하고 이를 구현하는 방법을 학습 한 다음 Flowers-17 및 CALTECH-101 데이터 세트에서 훈련 된 기계 학습 모델에 적용합니다.
24.1 Rank 정확도

왼쪽 : 신경망이 분류하려고하는 개구리의 입력 이미지. 오른쪽 : 자동차의 입력 이미지.
순위 정확도는 예를 통해 가장 잘 설명됩니다. 비행기, 자동차, 새, 고양이, 사슴, 개, 개구리, 말, 배, 트럭의 10 개 클래스를 포함하는 CIFAR-10 데이터 세트에서 훈련 된 신경망을 평가한다고 가정 해 보겠습니다.
다음 입력 이미지 (위 그림 왼쪽)가 주어지면 신경망에 각 클래스 레이블에 대한 확률을 계산하도록 요청합니다. 그러면 신경망은 아래 표 (왼쪽)에 나열된 클래스 레이블 확률을 반환합니다.
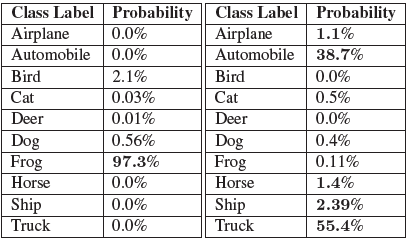
오른쪽 : 그림 (오른쪽)에 대해 네트워크에서 반환 한 클래스 레이블 확률.
왼쪽 : 그림 (왼쪽)에 대해 신경망이 반환 한 클래스 레이블 확률.
오른쪽 : 그림 (오른쪽)에 대해 네트워크에서 반환 한 클래스 레이블 확률.
확률이 가장 큰 클래스 레이블은 실제로 정확한 예측 인 frog (97.3 %)입니다. 이 과정을 반복한다면 :
1. 단계 # 1 : 데이터 셋의 각 입력 이미지에 대한 클래스 레이블 확률 계산.
2. 단계 # 2 : 실측 레이블이 확률이 가장 큰 예측 클래스 레이블과 같은지 확인합니다.
3. 단계 # 3 : 단계 # 2가 참인 횟수 집계.
우리는 rank-1 정확도에 도달 할 것입니다. 따라서 rank-1 정확도는 최상위 예측이 실측 레이블과 일치하는 예측의 백분율입니다. 이것은 우리가 계산하는 데 사용되는 “표준”유형의 정확도입니다. 올바른 예측의 총 수를 데이터 세트의 데이터 포인트 수로 나눕니다.
다음 이 개념을 rank-5 정확도로 확장 할 수 있습니다. 1위 예측에만 신경을 쓰지 않고 상위 5 개 예측에 신경을 씁니다. 평가 프로세스는 다음과 같습니다.
1. 1 단계 : 데이터 세트의 각 입력 이미지에 대한 클래스 레이블 확률을 계산합니다.
2. 2 단계 : 예측 된 클래스 레이블 확률을 내림차순으로 정렬하여 확률이 더 높은 레이블이 목록의 맨 앞에 배치되도록합니다.
3. 3 단계 : 2 단계의 상위 5 개 예측 레이블에 실측 레이블이 있는지 확인합니다.
4. 4 단계 : 단계 # 3이 참인 횟수를 계산합니다.
rank-5는 단순히 rank-1 정확도의 확장입니다. 분류기의 # 1 예측 만 고려하는 대신 네트워크의 상위 5 개 예측을 고려합니다. 예를 들어 임의의 신경망을 기반으로 CIFAR-10 범주로 분류 할 입력 이미지를 다시 고려해 보겠습니다 ( 위 그림 오른쪽). 네트워크를 통과 한 후 표 (오른쪽)에 자세히 설명 된 클래스 레이블 확률을 얻습니다. 우리의 이미지는 분명히 자동차입니다. 그러나 우리 네트워크는 트럭을 최상위 예측으로 보고했습니다. 이것은 1 순위 정확도에 대한 잘못된 예측으로 간주됩니다. 그러나 네트워크의 상위 5 개 예측을 살펴보면 자동차가 실제로 2 위 예측이라는 것을 알 수 있으며 이는 5 위 정확도를 계산할 때 정확합니다. 이 접근 방식은 임의의 랭크 N 정확도로 쉽게 확장 될 수 있습니다. 그러나 우리는 일반적으로 rank-1 및 rank-5 정확도 만 계산합니다.
질문을 하나 해보겠습니다. 왜 rank-5 정확도를 계산해야 할까요?
CIFAR-10 데이터 세트의 경우 rank-5 정확도를 계산하는 것은 약간 어리석은 일이지만 크고 어려운 데이터 세트, 특히 세분화 된 분류의 경우 특정 CNN에서 상위 5 개 예측을 보는 것이 도움이 되는 경우가 많습니다. 아마도 우리가 rank-1과 rank-5 정확도를 계산하는 이유에 대한 가장 좋은 예는 에는 시베리안 허스키, 오른쪽에는 에스키모 개가(아래 그림) 있는 Szegedy et al 논문 입니다. 대부분의 인간은 두 동물의 차이를 인식하지 못할 것입니다. 그러나 이 두 클래스는 ImageNet 데이터 세트에서 유효한 레이블입니다.

왼쪽 : 시베리안 허스키. 오른쪽 : 에스키모 개.
HDF5 LargeSize Data 딥러닝 인공지능 파이썬 python dataset
유사한 특성을 가진 많은 클래스 레이블을 포함하는 대규모 데이터 세트로 작업 할 때 네트워크 성능을 확인하기 위해 rank-1 정확도에 대한 확장으로 rank-5 정확도를 종종 검사합니다. 이상적인 세계에서 rank-1 정확도는 rank-5 정확도와 동일한 비율로 증가하지만 까다로운 데이터 세트에서는 항상 그런 것은 아닙니다.
따라서 우리는 네트워크가 이후 epoch에서 여전히 “학습 중”인지 확인하기 위해 rank-5 정확도도 조사합니다. rank-1 정확도가 훈련이 끝날 무렵 정체 되는 경우 일 수 있지만, 네트워크가 더 많은 차별적 기능을 학습함에 따라 rank-5 정확도가 계속 향상됩니다 (그러나 rank-1 예측을 추월 할만큼 차별적이지는 않음). 마지막으로 이미지 분류 문제 (ImageNet은 표준 예임)에 따라 rank-1 및 rank-5 정확도를 함께 보고해야합니다.