VGG16을 사용하여 특징을 추출 할 첫 번째 데이터 세트는 “Animals”데이터 세트입니다. 이 데이터 세트는 개, 고양이, 판다의 세 가지 클래스로 구성된 3,000 개의 이미지로 구성됩니다. VGG16을 활용하여 이러한 이미지에서 특징을 추출하려면 다음 명령을 실행하면 됩니다.

Titan X GPU를 사용하여 약 35 초 만에 3,000 개 이미지에서 특징을 추출 할 수있었습니다. 스크립트가 실행 된 후 animals / hdf5 디렉토리를 살펴보면 features.hdf5라는 파일을 찾을 수 있습니다.

Animals 데이터 세트의 .hdf5 파일을 조사하려면 Python 셸을 시작합니다.

HDF5 파일에 features, label_names 및 labels의 세 가지 데이터 세트가 있는지 확인하십시오. 피처 데이터 세트는 실제 추출 된 기능이 저장되는 곳입니다. 다음 명령어를 사용하여이 데이터 세트의 형태를 검사 할 수 있습니다.

.shape가 어떻게 (3000, 25088)인지 확인하십시오.이 결과는 Animals 데이터 세트의 각 이미지 3,000 개가 길이가 25,088 인 특성 벡터를 통해 정량화되었음을 의미합니다 (즉, 최종 POOL 작업 후 VGG16 내부 값). 이 장의 뒷부분에서 이러한 피처에 대해 분류기를 훈련하는 방법에 대해 알아 봅니다.
Animals 데이터 세트에서 특징을 추출한 것처럼 CALTECH-101로도 동일한 작업을 수행 할 수 있습니다.

이제 caltech-101 / hdf5 디렉토리에 features.hdf5라는 파일이 있습니다.

이 파일을 살펴보면 8,677 개의 이미지가 각각 25,088 차원의 특징 벡터로 표현된다는 것을 알 수 있습니다.
HDF5 LargeSize Data 딥러닝 인공지능 파이썬 python dataset
마지막으로 Flowers-17 데이터 세트에 CNN 특성 추출을 적용 해 보겠습니다.

Flowers-17에 대한 features.hdf5 파일을 살펴보면 데이터 세트의 각 1,360 개 이미지가 25,088 차원 특징 벡터를 통해 정량화 되었음을 알 수 있습니다.
이제 사전 훈련 된 CNN을 사용하여 소수의 데이터 세트에서 특성을 추출 했으므로 특히 VGG16이 Animals, CALTECH-101 또는 Flowers-17이 아닌 ImageNet에서 훈련 된 경우 이러한 특성이 실제로 얼마나 차별적인지 살펴 보겠습니다.
이제 두 번째로 간단한 선형 모델이 이러한 피처를 사용하여 이미지를 분류 할 때 얼마나 할 수 있는지 추측 해보십시오. 분류 정확도가 60 %보다 낫을까요? 70 %는 비합리적으로 보입니까? 확실히 80 %는 아닐까요? 그리고 90 %의 분류 정확도는 비현실적일까요?
새 파일을 열고 이름을 train_model.py로 지정하고 다음 코드를 삽입합니다.

2-7 행은 필수 Python 패키지를 가져옵니다. GridSearchCV 클래스는 매개 변수를 LogisticRegression 분류기로 바꾸는 데 사용됩니다. 학습 후 피클을 사용하여 LogisticRegression 모델을 디스크에 직렬화 합니다. 마지막으로 h5py가 사용되어 HDF5 기능 데이터 세트와 인터페이스 할 수 있습니다. 이제 명령 줄 인수를 구문 분석 할 수 있습니다.
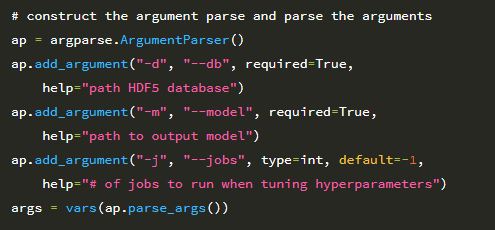
스크립트에는 두 개의 명령 줄 인수가 필요하며 세 번째는 옵션이 필요합니다.
1. –db : 추출 된 기능 및 클래스 레이블이 포함 된 HDF5 데이터 세트의 경로입니다.
2. –model : 여기서 출력 로지스틱 회귀 분류기에 대한 경로를 제공합니다.
3. –jobs : 하이퍼 파라미터를 로지스틱 회귀 모델에 맞게 조정하기 위해 그리드 검색을 실행할 때 동시 작업 수를 지정하는 데 사용되는 선택적 정수입니다.
HDF5 데이터 세트를 열고 학습 / 테스트 분할 위치를 결정하겠습니다.
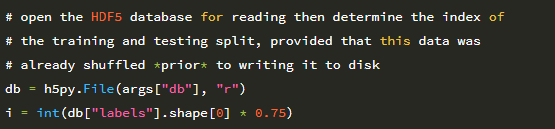
이 장의 앞부분에서 언급했듯이 관련 이미지 / 특징 벡터를 HDF5 데이터 세트에 쓰기 전에 의도적으로 이미지 경로를 섞었습니다. 그 이유는 22와 23행에서 명확 해집니다.
데이터 세트가 너무 커서 메모리에 맞지 않는 경우 , 우리는 훈련 및 테스트 분할을 결정하는 효율적인 방법이 필요합니다. HDF5 데이터 세트에 얼마나 많은 항목이 있는지 알고 있기 때문에 (그리고 우리는 데이터의 75 %를 훈련에 사용하고 25 %를 평가에 사용하고 싶다는 것을 알고 있기 때문에 데이터베이스에 75 % 인덱스 i를 간단히 계산할 수 있습니다. 인덱스 i 이전의 모든 데이터는 훈련 데이터로 간주됩니다. i 이후의 모든 데이터는 데이터를 테스트합니다.
훈련 및 테스트 분할을 고려하여 로지스틱 회귀 분류기를 훈련 해 보겠습니다.

28-31 행은 최적 값이 무엇인지 결정하기 위해 로지스틱 회귀 분류기의 엄격한 매개 변수 C에 대한 그리드 검색을 실행합니다. 로지스틱 회귀에 대한 자세한 검토는 여기 공부 범위를 벗어납니다. 로지스틱 회귀 분류기에 대한 자세한 검토는 Andrew Ng의 노트를 참조하십시오.
array 슬라이스를 통해 훈련 데이터와 훈련 레이블을 어떻게 표시하는지 확인하십시오.
다시 말하지만, 인덱스 i 이전의 모든 데이터는 훈련 세트의 일부입니다. 최상의 하이퍼 파라미터를 찾으면 테스트 데이터에서 분류기를 평가합니다 (36-38 행). 여기에서 테스트 데이터와 테스트 레이블은 배열 슬라이스를 통해 액세스됩니다.
인덱스 i 이후의 모든 것은 테스트 세트의 일부입니다. HDF5 데이터 세트가 디스크에 있고 (메모리에 맞기에는 너무 커서) NumPy 배열 인 것처럼 처리 할 수 있습니다. 이는 HDF5와 h5py를 딥 러닝 및 머신에 함께 사용하는 것의 큰 장점 중 하나입니다. 학습 과제. 마지막으로 LogisticRegression 모델을 디스크에 저장하고 데이터베이스를 닫습니다.
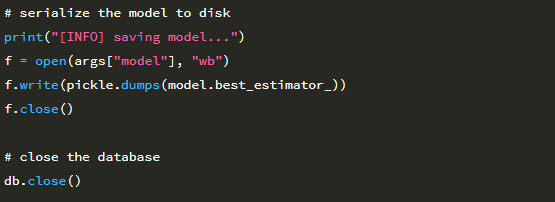
또한 Animals, CALTECH-101 또는 Flowers-17 데이터 세트와 관련된 특정 코드가 있는지 확인해 보십시오. 이미지의 입력 데이터 세트가 위의 33.2에 자세히 설명 된 디렉토리 구조를 준수하는 한 extract_features를 모두 사용할 수 있습니다. extract_feaures.py 및 train_model.py를 사용하여 CNN에서 추출한 기능을 기반으로 강력한 이미지 분류기를 빠르게 구축 할 수 있습니다.