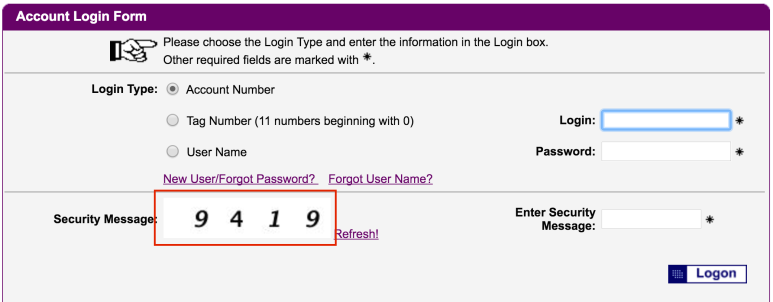
복사하는 경우 이 URL을 웹 브라우저에 붙여넣고 새로 고침을 여러 번 누르면 새로 고침 할 때마다 새 보안 문자를 생성하는 동적 프로그램임을 알 수 있습니다. 따라서 예제 보안 문자 이미지를 얻으려면이 이미지를 수백 번 요청하고 결과 이미지를 저장해야합니다.
새 보안 문자 이미지를 자동으로 가져 와서 디스크에 저장하려면 download_images.py를 사용할 수 있습니다.
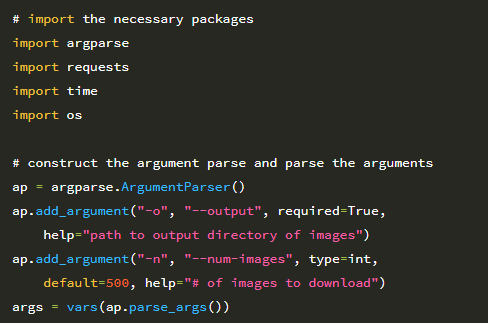
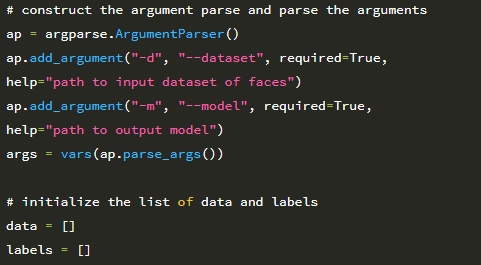
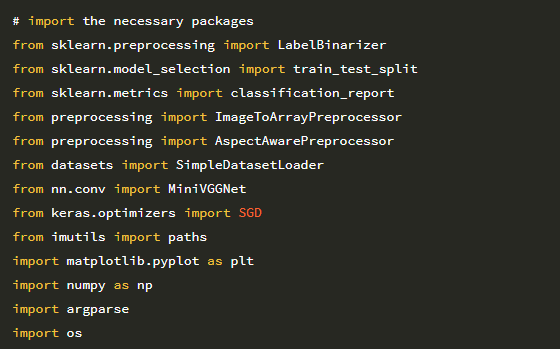
2 ~ 5 행은 필수 Python 패키지를 가져옵니다. requests 라이브러리는 HTTP 연결 작업을 쉽게 만들어 주며 Python 환경에서 많이 사용됩니다. 시스템에 아직 requests가 설치되어 있지 않은 경우 다음을 통해 설치할 수 있습니다.
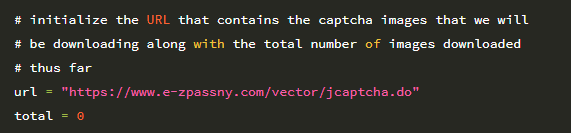
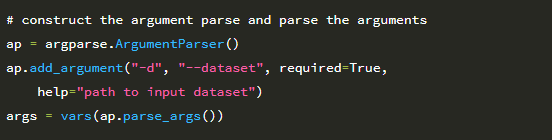
그런 다음 8-13 행에서 명령 줄 인수를 구문 분석합니다. 원시 보안 문자 이미지를 저장할 출력 디렉토리의 경로 인 단일 명령 줄 인수 –output이 필요합니다 (나중에 이미지의 각 숫자에 레이블을 지정합니다). 두 번째 옵션 인 –num-images 스위치는 다운로드 할 보안 문자 이미지의 수를 제어합니다. 이 값의 기본값은 총 500 개입니다. 각 보안 문자에 4 자리 숫자가 있으므로이 값 500은 네트워크 훈련에 사용할 수있는 총 500×4 = 2,000 자리 숫자를 제공합니다. 다음 코드 블록은 지금까지 생성 된 총 이미지 수와 함께 다운로드 할 보안 문자 이미지의 URL을 초기화합니다.
이제 captcha 이미지를 다운로드 할 준비가되었습니다.
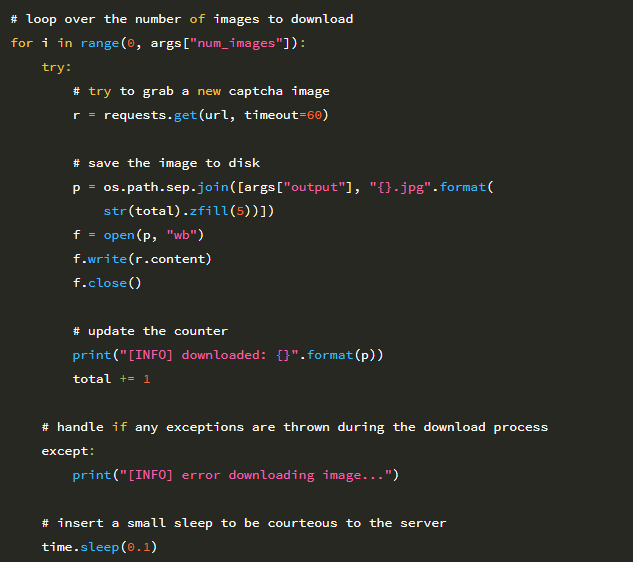
22 행에서 다운로드하려는 –num-images에 대해 반복을 시작합니다. 25 행에서 이미지 다운로드를 요청합니다. 그런 다음 28-32 행의 디스크에 이미지를 저장합니다. 이미지를 다운로드하는 중에 오류가 발생하면 39 행과 40 행의 try / except 블록이 이를 포착하고 스크립트를 계속할 수 있도록합니다. 마지막으로, 우리가 요청하는 웹 서버에 대한 부하를 줄이기 위해 43 번 줄에 작은 쉬는 모드를 삽입합니다. 다음 명령을 사용하여 download_images.py를 실행할 수 있습니다.
이 스크립트는 (1) 이미지 다운로드를 네트워크에 요청하고 (2) 다운로드 할 때마다 0.1 초의 일시 중지를 삽입했기 때문에 실행하는 데 시간이 걸립니다. 프로그램 실행이 완료되면 다운로드 디렉토리가 이미지로 채워진 것을 볼 수 있습니다.
그러나 이것은 원시 보안 문자 이미지 일뿐입니다. 훈련 세트를 만들기 위해 보안 문자의 각 숫자를 추출하고 레이블을 지정해야합니다. 이를 달성하기 위해 우리는 약간의 OpenCV 및 이미지 처리 기술을 사용하여 작업을 더 쉽게 만들 것입니다
지금까지 우리는 미리 컴파일되고 레이블이 지정된 데이터 세트로 작업했습니다.하지만 자체 사용자 지정 데이터 세트를 만든 다음 여기에서 CNN을 교육하려면 어떻게 해야 할까요? 이 장에서는 다음과 같은 예를 제공하는 완전한 딥러닝 사례를 제시합니다.
1. 이미지 세트 다운로드.
2. 교육을 위해 이미지에 레이블을 지정하고 주석을 추가합니다.
3. 사용자 지정 데이터 세트에서 CNN을 훈련합니다.
4. 훈련 된 CNN을 평가하고 테스트합니다.
다운로드 할 이미지 데이터 세트는 봇이 특정 웹 사이트에 자동으로 등록하거나 로그인하는 것을 방지하는 데 사용되는 보안 문자 이미지 세트입니다 (또는 더 나쁜 경우에는 다른 사람의 계정에 무차별 대입하려는 시도).
보안 문자 이미지 세트를 다운로드 한 후에는 보안 문자의 각 숫자에 수동으로 레이블을 지정해야합니다. 알게 되겠지만 데이터 세트를 얻고 라벨을 지정하는 것은 작업의 절반이 될 수 있습니다. 필요한 데이터의 양, 얻는 것이 얼마나 쉬운 지, 데이터에 레이블을 지정해야하는지 (예 : 이미지에 실제 레이블 지정) 여부에 따라 비용이 많이 드는 프로세스가 될 수 있습니다.
따라서 가능할 때마다 전통적인 컴퓨터 비전 기술을 사용하여 라벨링 프로세스의 속도를 높이려고 합니다. 이 장에서 Photoshop 또는 GIMP와 같은 이미지 처리 소프트웨어를 사용하여 captcha 이미지에서 숫자를 수동으로 추출하여 교육 세트를 만드는 경우 작업을 완료하는 데 며칠이 걸릴 수 있습니다.
그러나 몇 가지 기본적인 컴퓨터 비전 기술을 적용하면 한 시간 이내에 교육 세트를 다운로드하고 레이블을 지정할 수 있습니다. 이것이 제가 딥 러닝 실무자들에게 컴퓨터 비전 교육에 투자하도록 권장하는 여러 이유 중 하나입니다. 컴퓨터 비전에 적용되는 딥 러닝 마스터에 대해 진지하게 생각한다면 더 넓은 컴퓨터 비전 및 이미지의 기본 사항을 배우는 것이 좋습니다.
또한 실제 데이터 세트는 MNIST, CIFAR-10 및 ImageNet과 같은 벤치 마크 데이터 세트와 다릅니다. MNIST, CIFAR-10, ImageNet 등의 벤치 마크 데이터 세트는 이미지가 깔끔하게 분류되고 구성되고 평가할 수 있습니다. 이러한 벤치 마크 데이터 세트는 도전적 일 수 있지만 실제로는 (레이블이있는) 데이터 자체를 얻는 것이 쉽지 않습니다. 대부분의 경우 레이블이 지정된 데이터는 네트워크를 학습하여 얻은 딥러닝 모델보다 훨씬 더 가치가 있습니다.
예를 들어, 미국 정부를 위해 사용자 지정 자동 번호판 인식 (ANPR) 시스템을 만드는 회사를 운영하고 있다면 견고하고 방대한 데이터 세트를 구축하는 동시에 여러 딥러닝 접근 방식을 평가할 수 있습니다. 이렇게 레이블이 지정된 대규모 데이터 세트를 축적하면 다른 회사에 비해 경쟁력을 확보 할 수 있습니다.이 경우 데이터 자체가 최종 제품보다 더 가치가 있습니다. 레이블이 지정된 방대한 데이터 세트에 대한 독점적 권리 때문에 귀사가 인수 될 가능성이 더 높습니다.
번호판을 인식하는 놀라운 딥 러닝 모델을 구축하면 회사의 가치가 증가 할 뿐이지만 레이블이 지정된 데이터는 확보하고 복제하는 데 비용이 많이 들기 때문에 복제하기 어려운 (불가능하지는 않지만) 데이터 세트에 대한 키를 소유 하고있는 경우 회사의 주요 자산은 딥 러닝이 아니라 데이터입니다. 이 장의 나머지 부분에서는 이미지 데이터 세트를 얻고 레이블을 지정한 다음 딥 러닝을 적용하여 보안 문자 시스템을 뚷는 방법을 살펴 보겠습니다.
이 장은 체계적이고 읽기 쉽게 유지하기 위해 여러 부분으로 나뉩니다. 첫 번째 섹션에서는 우리가 작업하고있는 보안 문자 데이터 세트에 대해 논의하고 책임있는 공개의 개념에 대해 논의합니다. 컴퓨터 보안이 관련 될 때 항상해야 할 일입니다.
거기에서 우리 프로젝트의 디렉토리 구조에 대해 논의합니다. 그런 다음 학습 및 평가에 사용할 이미지 세트를 자동으로 다운로드하는 Python 스크립트를 만듭니다. 이미지를 다운로드 한 후에는 약간의 컴퓨터 비전을 사용하여 이미지에 레이블을 지정하는 데 도움을 주어야합니다. GIMP 또는 Photoshop과 같은 사진 소프트웨어 내에서 단순히 자르고 레이블을 지정하는 것보다 프로세스가 훨씬 쉽고 훨씬 빨라집니다. 데이터에 레이블을 지정하고 나면 LeNet 아키텍처를 교육 할 것입니다. 나중에 알게 되겠지만 보안 문자 시스템을 깨고 15 세대 미만으로 100 % 정확도를 얻을 수 있습니다.
참고 사항
책임있는 공개는 취약성을 공개하는 방법을 설명하는 컴퓨터 보안 용어입니다. 위협이 감지 된 직후 모든 사람이 볼 수 있도록 인터넷에 게시하는 대신 먼저 이해 관계자와 연락하여 문제가 있음을 확인합니다. 그런 다음 이해 관계자는 소프트웨어 패치를 시도하고 취약성을 해결할 수 있습니다. 단순히 취약성을 무시하고 문제를 숨기는 것은 잘못된 보안이므로 피해야합니다. 이상적인 세상에서는 취약점이 공개되기 전에 해결됩니다. 그러나 이해 관계자가 문제를 인정하지 않거나 적절한 시간 내에 문제를 해결하지 않으면 윤리적 수수께끼가 발생합니다.
이 지식은 어떠한 경우에도 사악하거나 비 윤리적 인 이유로 사용되어서는 안됩니다. 이 사례 연구는 사용자 지정 데이터 세트를 얻고 레이블을 지정하고 그 위에 딥 러닝 모델을 훈련시키는 방법을 보여주는 방법으로 존재합니다.
캡쳐 무력화 디렉토리 구조
보안 문자 무력화 시스템을 구축하려면 utils 하위 모듈을 업데이트하고 captchahelper.py라는 새 파일을 포함해야 합니다.
이 파일은 숫자를 심층 신경망에 공급하기 전에 숫자를 처리하는 데 도움이되는 preprocess라는 유틸리티 함수를 저장합니다. 또한 임의로 모듈 외부에 captcha_breaker라는 두 번째 디렉터리를 만들고 다음 파일과 하위 디렉터리를 포함합니다.
captcha_breaker 디렉토리는 이미지 캡차를 깨기 위해 모든 프로젝트 코드가 저장되는 곳입니다. 데이터 세트 디렉토리는 레이블이 지정된 숫자를 저장하는 곳입니다. 다음 디렉터리 구조 템플릿을 사용하여 데이터 세트를 구성하는 것을 선호합니다.
따라서 데이터 세트 디렉토리는 다음과 같은 구조를 갖습니다.
데이터 세트가 루트 디렉토리 인 경우 {1-9}는 가능한 숫자 이름이며 example.jpg는 주어진 숫자의 예입니다. 다운로드 디렉토리에는 E-ZPass 웹 사이트에서 다운로드 한 원시 captcha .jpg 파일이 저장됩니다. 출력 디렉토리 안에 훈련 된 LeNet 아키텍처를 저장합니다. 이름에서 알 수 있듯이 download_images.py 스크립트는 실제로 예제 캡차를 다운로드하여 디스크에 저장하는 역할을합니다.
캡차 세트를 다운로드 한 후에는 각 이미지에서 숫자를 추출하고 모든 숫자에 수동으로 라벨을 지정해야합니다. 이는 annotate.py로 수행됩니다.
train_model.py 스크립트는 레이블이 지정된 숫자에서 LeNet을 훈련시키는 반면 test_model.py는 LeNet을 captcha 이미지 자체에 적용합니다.
이제 모델을 학습 했으므로 다음 단계는 웹캠 / 비디오 파일에 액세스하고 각 프레임에 미소 감지를 적용하는 Python 스크립트를 빌드하는 것입니다. 이 단계를 수행하려면 새 파일을 열고 detect_smile.py라는 이름을 지정하면 작업을 시작합니다.
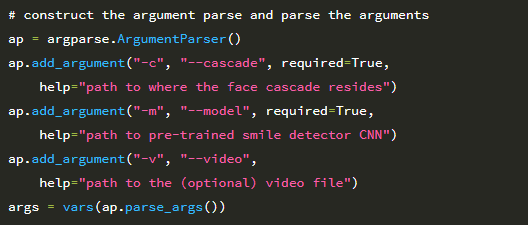
2-7 행은 필수 Python 패키지를 가져옵니다. img_to_array 함수는 비디오 스트림의 각 개별 프레임을 적절한 채널 순서 배열로 변환하는 데 사용됩니다. load_model 함수는 훈련 된 LeNet 모델의 가중치를 디스크에서 로드하는 데 사용됩니다. detectsmile.py 스크립트에는 두 개의 명령 줄 인수와 세 번째 선택적 인수가 필요합니다
첫 번째 인수 인 –cascade는 이미지에서 얼굴을 감지하는 데 사용되는 Haar 캐스케이드의 경로입니다. Paul Viola와 Michael Jones가 2001 년에 처음 발표한 논문 Rapid Object Detection using a Boosted Cascade of Simple Features 에서 언급되었으며, 이 출판물은 컴퓨터 비전 문헌에서 가장 많이 인용되는 논문 중 하나가되었습니다.
Haar 캐스케이드 알고리즘은 위치와 크기에 관계없이 이미지에서 물체를 감지 할 수 있습니다. 아마도 가장 흥미롭고 (그리고 우리 애플리케이션과 관련이있는) 감지기는 최신 하드웨어에서 실시간으로 실행될 수 있습니다. 실제로 Viola와 Jones의 작업 뒤에있는 동기는 얼굴 감지기를 만드는 것이 었습니다. 기존의 컴퓨터 비전 방법을 사용한 물체 감지에 대한 자세한 검토는 이 책의 범위를 벗어나므로 객체 감지를위한 일반적인 Histogram of Oriented Gradients + Linear SVM 프레임 워크와 함께 Haar 캐스케이드를 검토해야합니다.
두 번째 공통 라인 인수 –model은 디스크에서 직렬화 된 LeNet 가중치에 대한 경로를 지정합니다. 스크립트는 기본적으로 USB 웹캠에서 프레임을 읽는 것입니다. 그러나 대신 파일에서 프레임을 읽으려면 선택적 –video 스위치를 통해 파일을 지정할 수 있습니다.
웃는 얼굴 감지하기 전에 먼저 몇 가지 초기화를 수행해야합니다.
20과 21행은 각각 Haar 캐스케이드 얼굴 감지기와 사전 훈련된 LeNet 모델을 로드합니다. 비디오 경로가 제공되지 않은 경우 웹캠에 대한 포인터를 가져옵니다 (24 및 25 행). 그렇지 않으면 디스크의 비디오 파일에 대한 포인터를 엽니 다 (28 및 29 행).
이제 애플리케이션의 주요 처리 파이프 라인 입니다.
32 행은 (1) 스크립트를 중지하거나 (2) 비디오 파일의 끝에 도달 할 때까지 계속되는 루프를 시작합니다 (–video 경로가 적용된 경우).
34 행은 비디오 스트림에서 다음 프레임을 가져옵니다. 프레임을 잡을 수 없다면 비디오 파일의 끝에 도달 한 것입니다. 그렇지 않으면 300 픽셀 너비가 되도록 프레임 크기를 조정 (43 행)하고 그레이 스케일로 변환 (44 행)하여 얼굴 감지를 위해 프레임을 전처리합니다.
여기에서 회색조 이미지를 전달하고 주어진 영역이 얼굴로 간주 되려면 최소 너비가 30×30 픽셀이어야 함을 나타냅니다. minNeighbors 속성은 거짓양성 값을 제거하는 데 도움이 되며 scaleFactor는 생성 된 이미지 피라미드 수를 제어합니다.
.detectMultiScale 메서드는 프레임에서 얼굴을 경계하는 사각형을 구성하는 4 개의 튜플 목록을 반환합니다. 이 목록의 처음 두 값은 시작 (x, y) 좌표입니다. rects list 두 번째 두 값은 각각 경계 상자(bounding box)의 너비와 높이입니다.
아래에서 각 bounding box 세트를 반복합니다.
각 경계 상자에 대해 NumPy 어레이 슬라이싱을 사용하여 얼굴 ROI를 추출합니다 (58 행).
ROI가 확보되면 크기를 조정하고, 크기를 조정하고, Keras와 호환되는 배열로 변환하고, 이미지를 추가 차원으로 채움 (59-62 행)으로써 LeNet을 통해 분류를 준비합니다.
ROI가 사전 처리되면 분류를 위해 LeNet을 통과 할 수 있습니다.
66 번 줄에서 .predict를 호출하면 각각 “not smiling”및 “smiling”확률이 반환됩니다. 67 행은 어떤 확률이 더 큰지에 따라 레이블을 설정합니다. 레이블이 있으면 프레임의 해당 경계 상자와 함께 레이블을 그릴 수 있습니다
마지막 코드 블록은 출력 프레임을 화면에 표시하는 작업을 처리합니다.
q 키를 누르면 스크립트를 종료합니다. 웹캠을 사용하여 detect_smile.py를 실행하려면 다음 명령을 실행하십시오.
대신 비디오 파일을 사용하려면 –video 스위치를 사용하도록 명령을 업데이트합니다.
아래 그림에 미소 감지 스크립트의 결과를 포함했습니다.
LeNet이 내 표정을 기반으로 “미소”또는 “미소”를 올바르게 예측하는 방법을 확인하십시오.
이 장에서는 미소 감지를 수행하기 위해 종단 간 컴퓨터 비전 및 딥 러닝 애플리케이션을 구축하는 방법을 배웠습니다. 이를 위해 먼저 SMILES 데이터 세트에서 LeNet 아키텍처를 훈련했습니다.
SMILES 데이터 세트의 클래스 불균형으로 인해 문제를 완화하는 데 사용되는 클래스 가중치를 계산하는 방법을 발견했습니다.
훈련을 마친 후 테스트 세트에서 LeNet을 평가 한 결과 네트워크가 93 %의 뛰어난 분류 정확도를 얻었습니다. 더 많은 훈련 데이터를 수집하거나 기존 훈련 데이터에 데이터 증가를 적용하면 더 높은 분류 정확도를 얻을 수 있습니다.
그런 다음 웹캠 / 비디오 파일에서 프레임을 읽고 얼굴을 감지 한 다음 사전 훈련 된 네트워크를 적용하는 Python 스크립트를 만들었습니다. 얼굴을 감지하기 위해 OpenCV의 Haar 캐스케이드를 사용했습니다. 얼굴이 감지되면 프레임에서 추출한 다음 LeNet을 통해 사람이 웃고 있는지 여부를 확인했습니다. 전반적으로 우리의 미소 감지 시스템은 최신 하드웨어를 사용하여 CPU에서 실시간으로 쉽게 실행할 수 있습니다.
이 장에서는 전통적인 컴퓨터 비전 기술과 함께 딥 러닝을 사용하여 실시간으로 비디오 스트림에서 미소를 감지 할 수있는 완전한 end-to-end 애플리케이션을 구축 할 것입니다. 이 작업을 수행하기 위해 웃고, 있지 않은 사람들의 얼굴이 포함 된 이미지 데이터 세트에서 LetNet 아키텍처를 교육합니다. 네트워크가 훈련되면 별도의 Python 스크립트를 생성합니다.
이 스크립트는 OpenCV의 내장 Haar 캐스케이드 얼굴 감지기를 통해 이미지에서 얼굴을 감지하고 이미지에서 관심 영역 (ROI)을 추출한 다음 ROI를 미소 감지를 위해 LeNet을 통해 전달합니다.
이미지 분류를위한 실제 애플리케이션을 개발할 때 종종 기존의 컴퓨터 비전과 이미지 처리 기술을 딥 러닝과 혼합해야합니다. OpenCV 및 기타 컴퓨터 비전 기술에 대한 전체 검토는이 책의 범위를 벗어납니다. OpenCV 및 이미지 처리 기본 사항에 익숙해 지려면 OpenCV 다른 책을 읽어 보는 것이 좋습니다.
컴퓨터 비전 및 이미지 처리의 배경에 관계 없이 이 장을 마치면 자신의 응용 프로그램에서 사용할 수있는 완전한 미소 감지 솔루션을 사용합니다.
SMILES 데이터 세트는 웃거나 웃지 않는 얼굴의 이미지로 구성됩니다. 총 13,165 개의 그레이 스케일 이미지가 데이터 세트에 있으며 각 이미지의 크기는 64×64 픽셀입니다. 아래 그림에서 알 수 있듯이,이 데이터 세트의 이미지는 얼굴 주변에서 잘려서 입력 이미지에서 직접 “smiling”또는 “not smiling”패턴을 배울 수 있으므로 훈련 과정이 더 쉬워집니다. 이 책 앞부분의 유사한 작업을 했었던과 같습니다.
위 : “웃는”얼굴의 예. 아래 : “웃지 않는”얼굴 샘플. 이 장에서는 실시간 비디오 스트림에서 웃는 얼굴과 웃는 얼굴이 아닌 얼굴을 인식하는 컨볼 루션 신경망을 훈련 할 것입니다.
그러나 근접해 자르기는 테스트 중에 문제가됩니다. 입력 이미지에는 얼굴뿐만 아니라 이미지의 배경도 포함되므로 먼저 이미지에서 얼굴을 로컬라이즈 하기 전에 얼굴 ROI를 추출해야합니다. 운 좋게도 Haar cascades와 같은 전통적인 컴퓨터 비전 방법을 사용하면 생각보다 훨씬 쉬운 작업입니다.
SMILES 데이터 세트에서 처리해야하는 두 번째 문제는 클래스 불균형입니다. 데이터 세트에 13,165 개의 이미지가 있지만 이 예제 중 9,475 개는 not smiling이고 3,690 개만 smiling 클래스에 속합니다. “smiling”예제보다 “not smiling” 이미지의 수가 2.5 배 이상이라는 점을 감안할 때, 우리는 훈련 절차를 고안 할 때 주의해야합니다.
우리의 네트워크는 자연스럽게 “not smiling”레이블을 선택할 수 있습니다. 왜냐하면 (1) 분포가 고르지 않고 (2) “not smiling” 얼굴이 어떻게 생겼는지에 대한 더 많은 예가 있기 때문입니다.이 장의 뒷 부분에서 훈련 시간 동안 각 클래스의 “weight”를 계산하여 클래스 불균형을 해결할 수 있습니다.
미소 감지기를 구축하는 첫 번째 단계는 SMILES 데이터 세트에서 CNN을 훈련하여 미소 짓는 얼굴과 미소 짓지 않는 얼굴을 구분하는 것입니다. 이 작업을 수행하기 위해 train_model.py라는 새 파일을 만들어 보겠습니다. 다음 코드를 삽입하십시오.
2 ~ 14 행은 필수 Python 패키지를 가져옵니다. 이전에 모든 패키지를 사용했지만 LeNet (14 장) 클래스를 가져 오는 7행 에 주의 하십시오. 이것이 스마일 감지기를 만들 때 사용할 아키텍처입니다. 다음으로 명령 줄 인수를 구문 분석해 보겠습니다.
스크립트에는 두 개의 명령 줄 인수가 필요하며, 각 인수는 아래에서 자세히 설명합니다.
1. –dataset : 디스크에있는 SMILES 디렉토리의 경로입니다.
2. –model : 훈련 후 직렬화 된 LeNet 가중치가 저장되는 경로입니다. 이제 디스크에서 SMILES 데이터 세트를 로드하여 메모리에 저장할 준비가되었습니다.
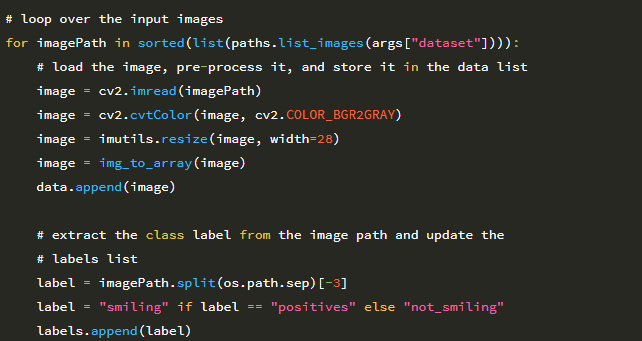
29 행에서는 –dataset 입력 디렉토리의 모든 이미지를 반복합니다. 이러한 각 이미지에 대해 다음을 수행합니다.
1. 디스크에서 로드합니다 (31 행).
2. 그레이 스케일로 변환합니다 (32 행).
3. 고정 입력 크기가 28 × 28 픽셀 (33 행)이 되도록 크기를 조정합니다.
4. 이미지를 Keras 및 채널 순서와 호환되는 배열로 변환합니다 (34 행).
5. LeNet이 학습 할 데이터 목록에 이미지를 추가합니다.
39-41 행은 imagePath에서 클래스 레이블을 추출하고 레이블 목록을 업데이트합니다. SMILES 데이터 세트는 웃는 얼굴을 SMILES / positives / positives7 하위 디렉토리에 저장하고 웃는 얼굴이 아닌 경우 SMILES / negatives / negatives7 하위 디렉토리에 있습니다.
따라서 이미지 경로를 보면 :
이미지 경로 구분자를 분할하고 마지막에서 세 번째 하위 디렉토리 인 positives를 잡아서 클래스 레이블을 추출 할 수 있습니다. 이 역할은 39행이 수행합니다.
이제 데이터와 레이블이 구성되었으므로 원시 픽셀 강도를 [0,1] 범위로 확장 한 다음 레이블에 원-핫 인코딩을 적용 할 수 있습니다
다음 코드 블록은 클래스 가중치를 계산하여 데이터 불균형 문제를 처리합니다.
52 행은 클래스 당 총 예제 수를 계산합니다. 이 경우 classTotals는 각각 “not smiling”및 “smiling”에 대한 [9475, 3690] array가 됩니다. 그런 다음 53 행에서 이 합계를 조정하여 클래스 불균형을 처리하는 데 사용되는 classWeight를 구하여 [1, 2.56] 배열을 생성합니다. 이 가중치는 우리 네트워크가 모든 “smiling” 인스턴스를 2.56 개의 “not smiling”인스턴스로 취급하고 “smiling” 예제를 볼 때 인스턴스 당 손실을 더 큰 가중치로 확대하여 클래스 불균형 문제를 해결하는 데 도움이 된다는 것을 의미합니다.
클래스 가중치를 계산 했으므로 이제 데이터의 80 %를 학습에 사용하고 20 %를 테스트에 사용하여 데이터를 학습 및 테스트 분할로 분할 할 수 있습니다.
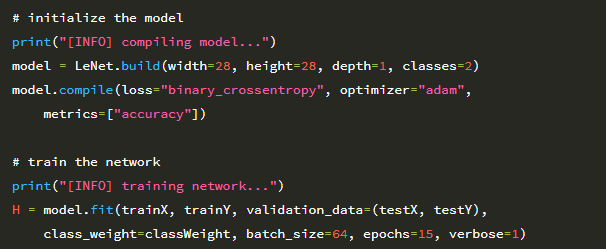
이제 LeNet으로 학습합니다.
62행은 28 × 28 단일 채널 이미지를 수용하는 LeNet 아키텍처를 초기화합니다. 두 개의 클래스 (smiling 또는 not smiling)만 있다는 점을 감안할 때 classes = 2를 설정합니다.
또한 손실 함수로 categorical_crossentropy 대신 binary_crossentropy를 사용할 것입니다. 다시 말하지만 범주형 교차 엔트로피는 클래스 수가 2 개 이상일 때만 사용됩니다.
지금까지 우리는 네트워크를 훈련하기 위해 SGD 최적화 프로그램을 사용해 왔습니다. 여기서는 Adam (63 행)을 사용합니다. 더 진보 된 옵티 마이저 (Adam, RMSprop, Adadelta 포함)는 나중에 다룹니다. 그러나 이 예제에서는 Adam이 특정 상황에서 SGD보다 빠르게 수렴 할 수 있다는 것만 이해하면 됩니다.
다시 말하지만, 옵티마이저 및 관련 매개 변수는 종종 네트워크를 훈련 할 때 조정해야 하는 초 매개 변수로 간주됩니다. 이 예제를 종합했을 때 Adam이 SGD보다 훨씬 더 나은 성과를 냈다는 것을 알게 되었습니다. 68과 69행은 클래스 불균형에 맞서기 위해 제공된 classWeight를 사용하여 총 15 epoch 동안 LeNet을 훈련시킵니다.
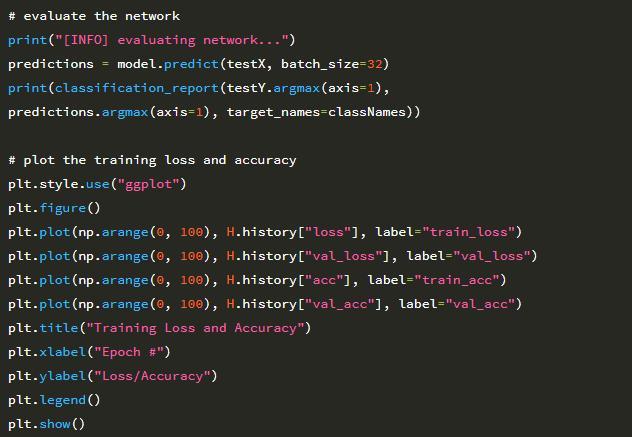
네트워크가 훈련되면 이를 평가하고 가중치를 디스크에 직렬화 할 수 있습니다.
또한 성능을 시각화 할 수 있도록 네트워크에 대한 학습 곡선을 구성 할 것입니다.
스마일 감지기를 훈련 시키려면 다음 명령을 실행하십시오.
15 epoch 후에 네트워크가 93 %의 분류 정확도를 얻고 있음을 알 수 있습니다. 아래 그림은 학습 곡선을 나타냅니다.
6 epoch 이후의 validation loss가 정체되기 시작합니다. 15 epoch 이후의 추가 훈련은 과적합을 초래합니다. 원하는 경우 다음과 같은 방법으로 더 많은 훈련 데이터를 사용하여 미소 감지기의 정확도를 향상시킬 수 있습니다.
1. 추가 훈련 데이터 수집.
2. 데이터 증가를 적용하여 기존 훈련 세트를 무작위로 변환, 회전 및 이동합니다. 데이터 증대는 나중에 자세히 다룹니다.
이 예에서는 이전 섹션과 동일한 학습 프로세스의 예를 하나만 추가하여 적용 할 것입니다. 데이터 augmentaion을 적용 할 것입니다. 데이터 augmentaion이 과적합을 방지하면서 분류 정확도를 높이는 방법을 확인하려면 새 파일을 열고 이름을 minivggnet_flowers17_data_aug.py로 지정한 다음 작업을 시작해 보겠습니다.
import는 데이터 증가에 사용되는 ImageDataGenerator 클래스를 가져 오는 9 행을 제외하고 minivggnet_flowers17.py에서와 동일합니다. 다음으로 명령 줄 인수를 구문 분석하고 이미지 경로에서 클래스 이름을 추출해 보겠습니다.
디스크에서 데이터 세트를로드하고 학습 / 테스트 분할을 구성하고 라벨을 인코딩합니다.
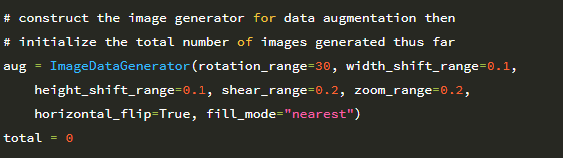
다음 코드 블록은 ImageDataGenerator를 초기화하므로 매우 중요합니다.
여기에서 이미지를 다음과 같이 설정할 수 있습니다.
1. 무작위로 ± 30도 회전
2. 수평 및 수직으로 0.2 배 이동
3. 0.2만큼 기울임
4. [0.8, 1.2] 범위에서 균일하게 샘플링하여 확대 / 축소
5. 무작위 수평으로 플립
정확한 데이터 세트에 따라 이러한 데이터 증가 값을 조정하고 싶을 것입니다. 응용 프로그램에 따라 [10,30] 사이의 회전 범위를 보는 것이 일반적입니다. 수평 및 수직 이동은 일반적으로 [0.1,0.2] 범위에 속합니다 (확대 / 축소 값도 동일). 이미지를 수평으로 뒤집 으면 클래스 레이블이 변경되지 않는 한 항상 수평 뒤집기를 포함해야합니다.
이전 실험에서와 같이 SGD 최적화 프로그램을 사용하여 MiniVGGNet을 학습합니다.
네트워크 훈련에 사용되는 코드는 이제 이미지 생성기를 사용하고 있으므로 약간 변경해야합니다
모델의 .fit 메서드를 호출하는 대신 이제 .fit_generator를 호출해야합니다. .fit_generator의 첫 번째 매개 변수는 훈련 데이터에서 새로운 훈련 샘플을 생성하는 데 사용되는 데이터 증가 함수 인 aug.flow입니다. aug.flow에서는 학습 데이터와 해당 레이블을 전달해야합니다. 또한 생성기가 네트워크를 훈련 할 때 적절한 배치를 구성 할 수 있도록 배치 크기를 제공해야합니다.
그런 다음 validation_data를 (testX, testY)의 2- 튜플로 제공합니다.이 데이터는 모든 epoch이 끝날 때 유효성 검사에 사용됩니다. steps_per_epoch 매개 변수는 epoch 당 배치 수를 제어합니다. 총 훈련 샘플 수를 배치 크기로 나누고 정수로 변환하여 적절한 steps_per_epoch 값을 프로그래밍 방식으로 결정할 수 있습니다. 마지막으로 epochs는 네트워크가 훈련되어야하는 총 epoch 수를 제어합니다 (이 경우 100 epoch). 네트워크를 훈련 한 후 이를 평가하고 해당 정확도 / 손실 플롯을 플로팅합니다
검증 데이터에 데이터 증가를 적용하지 않는 방법에 주목하십시오. 훈련 세트에만 데이터 증대를 적용합니다. 데이터 증가를 사용하여 Flowers-17에서 MiniVGGNet을 훈련하려면 다음 명령을 실행하십시오.
네트워크가 훈련을 마치면 즉시 정확도가 64 %에서 71 %로 증가하여 이전 실행보다 10.9 % 향상되었음을 알 수 있습니다. 그러나 정확성이 전부는 아닙니다. 실제 문제는 데이터 증대가 과적 합을 방지하는 데 도움이되었는지 여부입니다. 이 질문에 답하려면 아래 그림의 손실 및 정확도 플롯을 조사해야합니다.
MiniVGGNet을 데이터 증가로 Flowers-17에 적용합니다. 과적합은 여전히 문제입니다. 그러나 우리는 상당히 높은 분류 정확도와 낮은 손실을 얻을 수 있습니다.
여전히 과적합이 발생하고 있지만 데이터 증가를 사용하면 그 효과가 크게 감소합니다. 다시 말하지만,이 두 실험은 동일하다는 점을 명심하십시오. 우리가 만든 유일한 변경 사항은 데이터 증대 적용 여부 였습니다. 정규화에 영향을 미치는 데이터 증대를 확인할 수도 있습니다. 우리는 검증 정확도를 높일 수 있었기 때문에 훈련 정확도가 낮아 졌음에도 불구하고 모델의 일반화 가능성을 개선 할 수있었습니다.
시간이 지남에 따라 학습률을 감소 시키면 더 많은 정확도를 얻을 수 있습니다. 학습률은 이 장에서 특별히 제외되었으므로 Convolutional Neural Networks를 훈련 할 때 정규화자가 갖는 영향 데이터 증가에만 집중 하도록 합니다.
데이터 augmentation은 훈련 데이터에서 작동하는 정규화 기법의 한 유형입니다. 이름에서 알 수 있듯이 데이터 augmentation은 일련의 무작위 변환, 회전, 전단 및 뒤집기를 적용하여 훈련 데이터를 무작위로 변환합니다. 이러한 단순 변환을 적용해도 입력 이미지의 클래스 레이블은 변경되지 않습니다. 그러나 각 augmentation 이미지는 훈련 알고리즘이 이전에 보지 못했던 “새로운”이미지로 간주 될 수 있습니다. 따라서 우리의 훈련 알고리즘은 새로운 훈련 샘플과 함께 지속적으로 제공되어 더 강력하고 차별적인 패턴을 학습 할 수 있습니다.
결과에서 알 수 있듯이 데이터 증가를 적용하면 분류 정확도가 향상되는 동시에 과적합의 영향을 완화하는 데 도움이됩니다. 또한 데이터 증대를 통해 클래스 당 60 개의 샘플에 대해서만 Convolutional Neural Network를 훈련시킬 수있었습니다. 이는 클래스 당 제안 된 1,000 ~ 5,000 개 샘플보다 훨씬 적습니다.
“자연스러운”교육 샘플을 수집하는 것이 항상 더 좋지만, 데이터 확대는 작은 데이터 세트 제한을 극복하는 데 사용할 수 있습니다. 자신의 실험에 관해서는 실행하는 거의 모든 실험에 데이터 augmentation을 적용해야합니다. CPU가 입력을 무작위로 변환하는 룰이 있기 때문에 약간의 성능 저하가 있습니다. 그러나 이 성능 저하는 스레딩을 사용하고 네트워크 훈련을 담당하는 스레드로 전달되기 전에 백그라운드에서 데이터를 보강하여 완화됩니다.
시간을내어 이 기술에 익숙해지면 더 나은 성능의 딥 러닝 모델 (더 적은 데이터 사용)을 더 빨리 얻을 수 있습니다.
시작하려면 Flowers-17 데이터 세트에서 MiniVGGNet 아키텍처 (16 장)를 학습 할 때 데이터 증가를 사용하지 않는 기준을 설정해 보겠습니다. 새 파일을 열고 이름을 minivggnet_flowers17.py로 지정하면 작업을 시작할 수 있습니다.
2 ~ 14 행은 필수 Python 패키지를 가져옵니다. 이전에 본 대부분의 import는 다음과 같습니다.
1. 6행 : 여기에서 새로 정의 된 AspectAwarePreprocessor를 가져옵니다.
2. 7 행 : 별도의 이미지 전처리기를 사용 함에도 불구하고 SimpleDatasetLoader를 사용하여 디스크에서 데이터 세트를로드 할 수 있습니다.
3. 8 행 : 데이터 세트에서 MiniVGGNet 아키텍처를 학습합니다.
다음으로 명령 줄 인수를 구문 분석합니다.
여기에는 디스크에있는 Flowers-17 데이터 세트 디렉토리의 경로 인 –dataset이라는 단일 스위치 만 필요합니다.
계속해서 입력 이미지에서 클래스 레이블을 추출해 보겠습니다.
Flowers-17 데이터 세트는 다음과 같은 디렉토리 구조를 가지고 있습니다.
데이터 세트의 이미지 예는 다음과 같습니다.
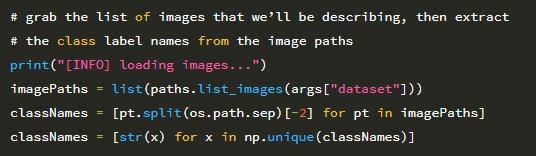
따라서 클래스 레이블을 추출하기 위해 경로 구분 기호 (26 행)를 분할 한 후 두 번째에서 마지막 인덱스를 추출하여 bluebell 텍스트를 생성 할 수 있습니다. 이 경로 및 레이블 추출이 어떻게 작동하는지 확인하는 데 어려움을 겪는 경우 Python 셸을 열고 파일 경로 및 경로 구분 기호를 사용하는 것이 좋습니다. 특히 운영 체제의 경로 구분 기호를 기반으로 문자열을 분할 한 다음 Python 인덱싱을 사용하여 배열의 다양한 부분을 추출하는 방법에 유의하십시오.
그런 다음 27 행은 이미지 경로에서 고유 한 클래스 레이블 집합 (이 경우 총 17 개의 클래스)을 결정합니다. imagePaths가 주어지면 디스크에서 Flowers-17 데이터 세트를 로드 할 수 있습니다
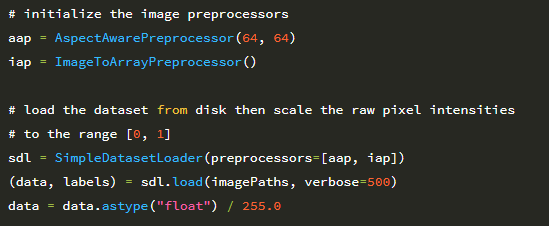
30 행은 AspectAwarePreprocessor를 초기화하여 처리하는 모든 이미지가 64×64 픽셀이되도록 합니다. 그러면 ImageToArrayPreprocessor가 31 행에서 초기화되어 이미지를 Keras 호환 배열로 변환 할 수 있습니다. 그런 다음 각각이 두 전처리기를 사용하여 SimpleDatasetLoader를 인스턴스화합니다 (35 행).
데이터 및 해당 레이블은 36 행에서 디스크에서 로드됩니다. 그런 다음 데이터 배열의 모든 이미지는 원시 픽셀 강도를 255로 나누어 [0,1] 범위로 정규화됩니다. 이제 데이터가 로드 되었으므로 학습을 수행 할 수 있습니다. 라벨을 원-핫 인코딩과 함께 테스트 분할 (학습용 75 %, 테스트 용 25 %) 합니다.
꽃 분류기를 훈련하기 위해 SGD 최적화 프로그램과 함께 MiniVGGNet 아키텍처를 사용합니다.
MiniVGGNet 아키텍처는 64 × 64 × 3 (너비 64 픽셀, 높이 64 픽셀, 채널 3 개)의 공간 크기 이미지를 허용합니다. 총 클래스 수는 len (classNames)이며,이 경우 Flowers-17 데이터 세트의 각 카테고리에 대해 하나씩해서 17 개입니다.
초기 학습률 α = 0.05로 SGD를 사용하여 MiniVGGNet을 훈련합니다. 다음 섹션에서 데이터 증가가 미치는 영향을 입증 할 수 있도록 의도적으로 학습률 감소를 제외 할 것입니다. 58 행과 59 행은 MiniVGGNet을 총 100 epoch 동안 훈련합니다. 그런 다음 네트워크를 평가하고 시간에 따른 손실과 정확도를 플로팅합니다.
MiniVGGNet을 사용하여 Flowers-17에 대한 기준 정확도를 얻으려면 다음 명령을 실행하십시오.
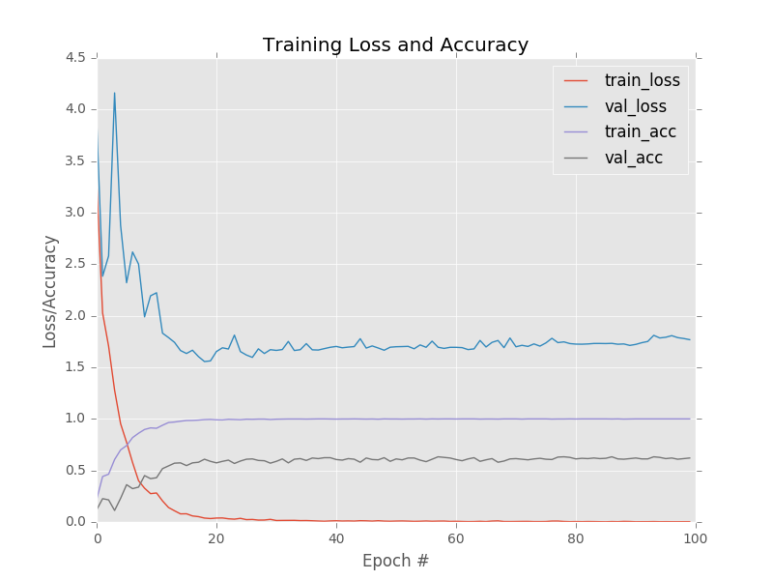
출력에서 볼 수 있듯이, 제한된 양의 훈련 데이터를 고려할 때 상당히 합리적인 64 %의 분류 정확도를 얻을 수 있습니다. 그러나 우려되는 것은 손실 및 정확도 플롯입니다 아래 그림에서 알 수 있듯이 네트워크는 Epoch 20을 지나서 빠르게 과적합 되기 시작합니다. 이유는 클래스 당 60 개의 이미지가있는 1,020 개의 학습 예제 만 있기 때문입니다 (다른 이미지는 테스트에 사용됩니다.) Convolutional Neural Network를 훈련 할 때 클래스 당 1,000-5,000 개의 예제가 이상적으로 있어야한다는 점을 명심하십시오.
데이터 증대없이 Flowers-17 데이터 셋에 적용된 MiniVGGNet의 학습 플롯. 검증 손실이 증가함에 따라 epoch 25 이후에 과적 합이 어떻게 시작되는지 주목하십시오.
더욱 이 훈련 정확도는 처음 몇 epoch에서 95 %를 초과하여 급등하여 결국에는 100 % 정확도를 얻습니다.이 출력은 과적합의 분명한 경우입니다. 상당한 학습 데이터가 부족하기 때문에 MiniVGGNet은 학습 데이터의 기본 패턴을 너무 가깝게 모델링하고 테스트 데이터로 일반화 할 수 없습니다.
과적합을 방지하기 위해 정규화 기술을 적용 할 수 있습니다.이 장의 맥락에서 정규화 방법은 데이터 증가입니다. 실제로는 과적합의 영향을 더 줄이기 위해 다른 형태의 정규화 (weight decay, 드롭 아웃 등)도 포함 됩니다.
이 섹션의 첫 번째 부분에서는 매우 작은 데이터 세트 인 Flowers-17 데이터 세트 (컴퓨터 비전 작업을위한 딥러닝 측면에서)에 대해 설명하고 데이터 증가가 이 데이터 세트의 크기를 추가 교육 샘플이 어떻게 도움이 되는지 여기에서 두 가지 실험을 수행합니다.
1. 데이터 augmentation없이 Flowers-17에서 MiniVGGNet을 훈련시킵니다.
2. 데이터 augmentation을 사용하여 Flowers-17에서 MiniVGGNet을 훈련시킵니다.
곧 알게 되겠지만 데이터 증대를 적용하면 과적합이 크게 줄어들고 MiniVGGNet이 훨씬 더 높은 분류 정확도를 얻을 수 있습니다.
22.3.1 Flowers-17 데이터 세트
Flowers-17 데이터 세트 [10]는 17 개의 서로 다른 꽃 종을 인식하는 세분화 된 분류 과제입니다. 이미지 데이터 세트는 매우 작으며 총 1,360 개의 이미지에 대해 클래스 당 80 개의 이미지 만 있습니다. 컴퓨터 비전 작업에 딥러닝을 적용 할 때 일반적인 경험 법칙은 수업 당 1,000 ~ 5,000 개의 예제를 포함하는 것이므로 여기서는 확실히 부족합니다. 모든 범주가 매우 유사하기 때문에 Flowers-17을 fined-graied 분류작업이라고 부릅니다 (예 : 꽃 종).
각 클래스가 특정 꽃 종을 나타내는 Flowers-17 데이터 세트의 5 개 (총 17 개 중) 클래스 샘플.
사실 우리는 이러한 각 범주를 하위 범주로 생각할 수 있습니다. 카테고리는 확실히 다르지만 상당한 양의 공통 구조를 공유합니다.(꽃잎, 수술, 암술 등) fine-grained 분류 작업은 기계 학습 모델이 매우 유사한 클래스를 구별하기 위해 극도로 구별되는 기능을 학습해야 함을 의미하므로 딥러닝 실무자에게 가장 어려운 경향이 있습니다. 이 세분화 된 분류 작업은 제한된 훈련 데이터를 고려할 때 훨씬 더 문제가됩니다.
Flowers-17 데이터 다운로드$ curl -LO http://www.robots.ox.ac.uk/~vgg/data/flowers/17/17flowers.tgz $ tar -xzf 17flowers.tgz
이제 모든 이미지가 jpg라는 폴더에 있습니다. 이러한 이미지를 flower_dataset / train 및 flower_dataset / test 디렉토리로 분할합니다. 각 디렉토리에는 split.py를 사용하여 17 개의 꽃 클래스에 해당하는 하위 디렉토리가 포함되어 있습니다.
split.py 파일을 실행합니다. train 디렉토리에는 각 클래스에 대해 70 개의 이미지가 포함되고 test 디렉토리에는 각 클래스에 대해 10 개의 이미지가 포함됩니다.
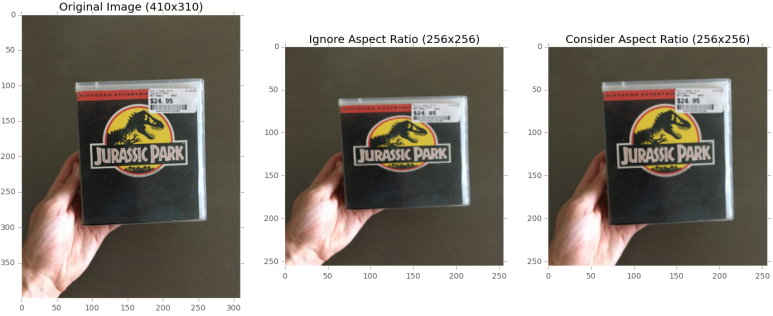
지금까지는 영상 비를 무시하고 고정 된 크기로 크기를 조정하여 이미지 만 전처리했습니다. 일부 상황에서, 특히 기본 벤치마크 데이터 세트의 경우 그렇게하는 것이 허용됩니다. 그러나 더 까다로운 데이터 세트의 경우 고정 된 크기로 크기를 조정하되 종횡비를 유지해야합니다. 이 동작을 시각화하려면 아래 그림을 보십시오
왼쪽 : 원본 입력 이미지 (410 × 310).
중간 : 화면 비율을 무시하고 이미지 크기를 256×256 픽셀로 조정합니다. 이제 이미지가 찌그러지고 왜곡 된 것처럼 보입니다.
오른쪽 : 가로 세로 비율을 유지하면서 이미지 크기를 256 × 256으로 조정합니다.
왼쪽에는 고정 된 너비와 높이로 크기를 조정해야하는 입력 이미지가 있습니다. 가로 세로 비율을 무시하고 이미지 크기를 256 × 256 픽셀 (가운데)로 조정하여 원하는 크기에 맞도록 효과적으로 이미지를 찌그러 뜨리고 왜곡합니다. 더 나은 접근 방식은 이미지의 종횡비 (오른쪽)를 고려하는 것입니다. 먼저 너비가 256 픽셀이되도록 더 짧은 치수를 따라 크기를 조정 한 다음 높이를 따라 이미지를 자르고 높이가 256 픽셀이 되도록합니다. 자르는 동안 이미지의 일부를 효과적으로 버렸지 만 이미지의 원래 종횡비도 유지했습니다. 일관된 종횡비를 유지하면 Convolutional Neural Network가보다 차별적이고 일관된 기능을 학습 할 수 있습니다. aspect-aware 전처리가 어떻게 구현되는지 확인하기 위해 AspectAwarePreprocessor를 포함하도록 프로젝트 구조를 업데이트 해 보겠습니다.
전처리 하위 모듈 내에 aspectawarepreprocessor.py라는 새 파일을 추가 한 방법에 주목하십시오. 이 위치는 새 전처리기가 있을 위치입니다. aspectawarepreprocessor.py를 열고 다음 코드를 삽입하십시오
SimplePreprocessor에서와 마찬가지로 생성자는 이미지 크기를 조정할 때 사용되는 보간 방법과 함께 두 개의 매개 변수 (대상 출력 이미지의 원하는 너비 및 높이)가 필요합니다. 그런 다음 아래에서 전처리 기능을 정의 할 수 있습니다.
전처리 함수는 전처리하려는 이미지인 단일 인수를받습니다.
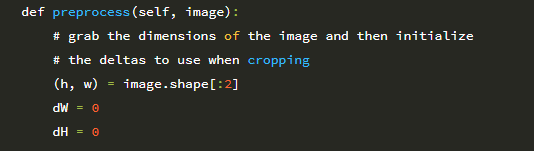
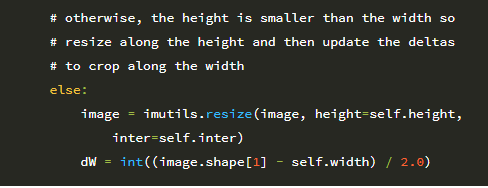
16 행은 입력 이미지의 너비와 높이를 잡고, 17 행과 18 행은 더 큰 치수를 따라 자를 때 사용할 델타 오프셋을 결정합니다. 다시 말하지만, 비율 인식 전처리 기는 2 단계 알고리즘입니다.
1. 단계 # 1 : 가장 짧은 치수를 결정하고 그에 따라 크기를 조정합니다.
2. 단계 # 2 : 목표 너비와 높이를 얻기 위해 가장 큰 치수를 따라 이미지를 자릅니다.
다음 코드 블록은 너비가 높이보다 작은 지 확인하고, 그렇다면 너비를 따라 크기를 조정합니다.
그렇지 않고 높이가 너비보다 작으면 높이를 따라 크기를 조정합니다.
이제 이미지의 크기가 조정되었으므로 너비와 높이를 다시 잡고 델타를 사용하여 이미지 중앙을 잘라야합니다.
잘라낼 때 (반올림 오류로 인해) 이미지 대상 이미지 크기가 ± 1 픽셀만큼 벗어날 수 있습니다. 따라서 출력 이미지가 원하는 너비와 높이를 갖도록 cv2.resize를 호출합니다. 그런 다음 전처리 된 이미지가 호출 함수로 반환됩니다. AspectAwarePreprocessor를 구현 했으므로 이제 Flowers-17 데이터 세트에서 MiniVGGNet 아키텍처를 학습 할 때 작동하도록 하겠습니다.
Goodfellow et al.에 따르면, 정규화는 “일반화 오류를 줄이기 위한 학습 알고리즘의 수정이 훈련 오류를 줄이려는 것이 아닙니다.”. 간단히 말해서 정규화는 훈련 오류를 약간 증가시키는 대신 테스트 오류를 줄이려고 합니다.
이미 앞 8 장에서 다양한 형태의 정규화를 살펴 보았습니다. 그러나 이는 매개 변수화 된 정규화 형식이어서 손실 / 업데이트 함수를 업데이트해야합니다. 실제로 다음과 같은 다른 유형의 정규화 방법이 있습니다.
1. 네트워크 아키텍처 자체를 수정합니다.
2. 훈련을 위해 네트워크로 전달되는 데이터를 확장합니다.
드롭 아웃은 일반화 가능성을 높여 네트워크 아키텍처를 수정하는 좋은 예입니다. 이전 계층에서 다음 계층으로 노드를 무작위로 연결 해제하는 계층을 삽입하여 단일 노드가 주어진 클래스를 나타내는 방법을 학습하지 않도록 하는 것입니다.
이 장의 나머지 부분에서는 데이터 증강이라는 또 다른 유형의 정규화에 대해 설명합니다. 이 방법은 훈련 예제를 훈련을 위해 네트워크로 전달하기 전에 의도적으로 훈련 예제를 교란시키고 모양을 약간 변경합니다.
최종 결과는 네트워크가 원래 훈련 데이터에서 생성 된 “새로운” 훈련 데이터 포인트를 지속적으로 확인하여 더 많은 훈련 데이터를 수집해야 하는 필요성을 부분적으로 완화합니다 (일반적으로 더 많은 훈련 데이터를 수집해도 알고리즘에는 거의 영향을 미치지 않음).
22.1 데이터 증강이란 무엇인가?
데이터 증가는 클래스 레이블이 변경되지 않도록 임의의 지터 및 교란을 적용하여 원본에서 새로운 훈련 샘플을 생성하는 데 사용되는 광범위한 기술을 포함합니다. 데이터 증대를 적용 할 때 우리의 목표는 모델의 일반화 가능성을 높이는 것입니다. 네트워크가 지속적으로 약간 수정 된 새 버전의 입력 데이터 포인트를 보고 있다는 점을 감안할 때 더 강력한 기능을 학습 할 수 있습니다. 테스트시에는 데이터 증대를 적용하지 않고 훈련 된 네트워크를 평가하지 않습니다. 대부분의 경우 훈련 정확도가 약간 떨어지더라도 테스트 정확도가 향상되는 것을 확인할 수 있습니다.
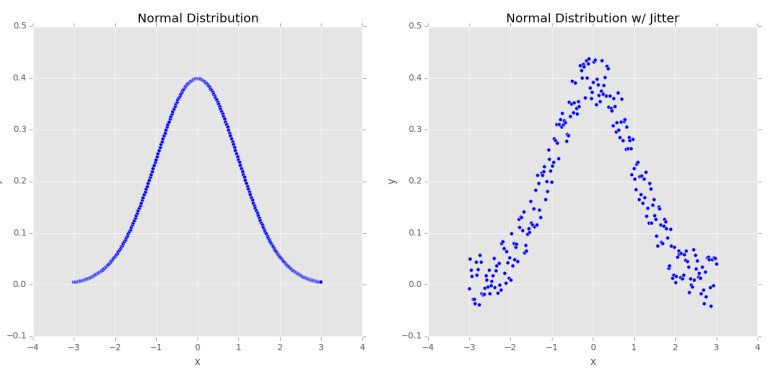
왼쪽 : 정규 분포를 정확히 따르는 250 개의 데이터 포인트 샘플.
오른쪽 : 소량의 무작위 “지터”를 분포에 추가합니다. 이러한 유형의 데이터 증대는 네트워크의 일반화 가능성을 높일 수 있습니다.
평균이 0이고 단위 분산이있는 정규 분포의 위 그림 (왼쪽)을 고려해 보겠습니다. 이 데이터에 대한 기계 학습 모델을 학습하면 분포를 정확하게 모델링 할 수 있습니다. 그러나 실제 애플리케이션에서는 데이터가 이러한 깔끔한 분포를 거의 따르지 않습니다.
대신, 분류기의 일반화 가능성을 높이기 위해 먼저 무작위 분포 (오른쪽)에서 가져온 일부 값 ε을 추가하여 분포를 따라 점을 무작위로 지 터링 할 수 있습니다. 우리의 플롯은 여전히 대략 정규 분포를 따르지만 왼쪽과 같이 완벽한 분포는 아닙니다. 이 데이터에 대해 훈련 된 모델은 훈련 세트에 포함되지 않은 예제 데이터 포인트로 일반화 될 가능성이 더 높습니다.
컴퓨터 비전의 맥락에서 데이터 증강은 자연스러운 것입니다. 예를 들어, 무작위와 같은 간단한 기하학적 변환을 적용하여 원본 이미지에서 추가 훈련 데이터를 얻을 수 있습니다. (작은) 입력 이미지에 대한 이러한 변환의 양은 모양이 약간 변경되지만 클래스 레이블은 변경되지 않습니다. 따라서 데이터 증가는 컴퓨터 비전 작업을위한 딥 러닝에 적용 할 수있는 매우 자연스럽고 쉬운 방법입니다. 컴퓨터 비전에 적용되는 데이터 증대를위한보다 진보 된 기술에는 주어진 색 공간에서 색상의 무작위 교란과 비선형 기하학적 왜곡이 있습니다.
컴퓨터 작업에 적용되는 데이터 증가를 이해하는 가장 좋은 방법은 주어진 입력이 증가되고 왜곡되는 것을 시각화하는 것입니다. 이 시각화를 수행하기 위해 Keras의 내장 된 기능을 사용하여 데이터 증대를 수행하는 간단한 Python 스크립트를 작성해 보겠습니다. 새 파일을 만들고 이름을 augmentation_demo.py로 지정합니다. 다음 코드를 삽입하십시오.
2-6 행은 필수 Python 패키지를 가져옵니다. Keras에서 ImageDataGenerator 클래스를 가져 오는 2 행을 기억해 두십시오.이 코드는 데이터 증가에 사용되며 입력 이미지를 변환하는 데 도움이되는 모든 관련 메서드를 포함합니다. 다음으로 명령 줄 인수를 구문 분석합니다.
스크립트에는 세 개의 명령 줄 인수가 필요합니다. 각 인수는 아래에 자세히 설명되어 있습니다.
• –image : 데이터 증가를 적용하고 결과를 시각화하려는 입력 이미지의 경로입니다.
• –output : 주어진 이미지에 데이터 증가를 적용한 후 검사 할 수 있도록 결과를 디스크에 저장하려고합니다.이 스위치는 출력 디렉토리를 제어합니다.
• –prefix : 출력 이미지 파일 이름 앞에 추가 할 문자열입니다.
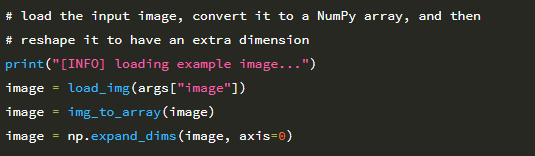
이제 명령 줄 인수가 구문 분석되었으므로 입력 이미지를로드하고 Keras 호환 배열로 변환하고 이미지 분류를 위해 준비 할 때처럼 이미지에 차원을 추가합니다.
이제 ImageDataGenerator를 초기화 할 준비가되었습니다.
ImageDataGenerator 클래스에는 이 책에서 열거하기에는 너무 많은 매개 변수가 있습니다. 매개 변수에 대한 전체 검토는 공식 Keras 문서 (http://pyimg.co/j8ad8)를 참조하십시오.
대신 자체 애플리케이션에서 가장 많이 사용할 augmentation 매개 변수에 초점을 맞출 것입니다. rotation_range 매개 변수는 임의 회전의 각도 범위를 제어합니다. 여기에서 입력 이미지를 무작위로 ± 30도 회전 할 수 있습니다. width_shift_range 및 height_shift_range는 각각 수평 및 수직 이동에 사용됩니다. 매개 변수 값은 주어진 차원의 일부입니다 (이 경우 10 %).
shear_range는 이미지를 기울일 수있는 라디안으로 시계 반대 방향의 각도를 제어합니다. 그런 다음 [1-zoom_range, 1 + zoom_range] 값의 균일 한 분포에 따라 이미지를 “확대”또는 “축소”할 수있는 부동 소수점 값인 zoom_range가 있습니다.
마지막으로 horizontal_flip 부울은 주어진 입력이 훈련 과정에서 수평으로 뒤집힐 수 있는지 여부를 제어합니다. 대부분의 컴퓨터 비전 응용 프로그램의 경우 이미지의 수평 반전은 결과 클래스 레이블을 변경하지 않지만 수평 (또는 수직) 반전이 이미지의 의미를 변경하는 응용 프로그램이 있습니다.
우리의 목표는 입력 이미지를 약간 수정하여 클래스 레이블 자체를 변경하지 않고 새로운 학습 샘플을 생성하는 것이므로 이러한 유형의 데이터 증가를 적용 할 때는주의하십시오. ImageDataGenerator가 초기화되면 실제로 새로운 학습 예제를 생성 할 수 있습니다.
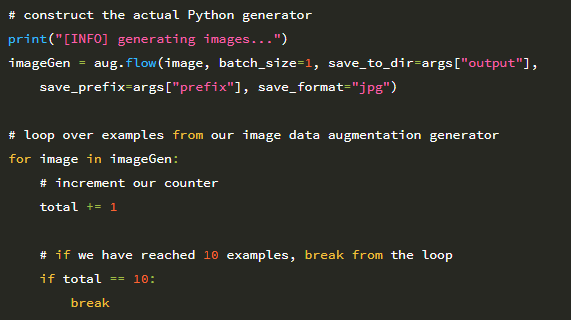
34 행과 35 행은 증강 이미지를 구성하는 데 사용되는 Python 생성기를 초기화합니다. 출력 이미지 파일 경로, 각 파일 경로의 접두사 및 이미지 파일 형식을 지정하는 몇 가지 추가 매개 변수와 함께 입력 이미지 인 batch_size 1을 전달합니다 (하나의 이미지 만 증가 시키므로). 그런 다음 38 행은 imageGen 생성기의 각 이미지를 반복하기 시작합니다. 내부적으로 imageGen은 루프를 통해 요청 될 때마다 새로운 학습 샘플을 자동으로 생성합니다. 그런 다음 디스크에 기록 된 총 데이터 증가 예제 수를 늘리고 예제 10 개에 도달하면 스크립트 실행을 중지합니다.
실제 데이터 증가를 시각화하기 위해 우리는 Jemma의 이미지 인 아래 그림(왼쪽)를 사용합니다. Jemma의 새로운 학습 예제 이미지를 생성하려면 다음 명령을 실행하십시오.
스크립트가 실행 된 후 출력 디렉토리에 10 개의 이미지가 표시되어야합니다.
왼쪽 : 데이터 augmentation을 적용 할 입력 이미지입니다.
오른쪽 : 데이터 augmentation 예제의 몽타주. 각 이미지가 어떻게 무작위로 회전하고, 기울이고, 확대되고, 수평으로 뒤집 혔는지 확인하십시오.
위 그림 (오른쪽)에서 시각화 할 수 있도록 각 이미지의 몽타주를 구성했습니다. 각 이미지가 어떻게 무작위로 회전하고, 기울이고, 확대되고, 수평으로 뒤집 혔는지 확인하십시오. 각각의 경우 이미지는 원래 클래스 레이블 dog 을 유지합니다. 그러나 각 이미지가 약간 수정되어 훈련 할 때 배울 수있는 새로운 패턴을 신경망에 제공합니다. 입력 이미지는 지속적으로 변경되기 때문에 (클래스 레이블은 동일하게 유지됨) 데이터 증가가없는 학습과 비교할 때 학습 정확도가 감소하는 것이 일반적입니다.
그러나이 장의 뒷부분에서 살펴 보 겠지만 데이터 확대는 과적합을 크게 줄이는 데 도움이 될 수 있으며, 동시에 모델이 새로운 입력 샘플에 더 잘 일반화되도록 보장합니다. 또한 딥러닝을 적용하기에는 예제가 너무 적은 데이터 세트로 작업 할 때 데이터 증강을 활용하여 추가 훈련 데이터를 생성 할 수 있으므로 딥 러닝 네트워크를 훈련하는 데 필요한 수동 레이블 데이터의 양을 줄일 수 있습니다.
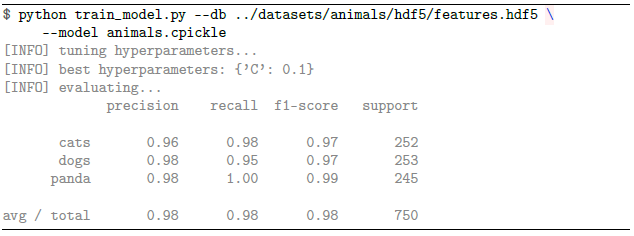
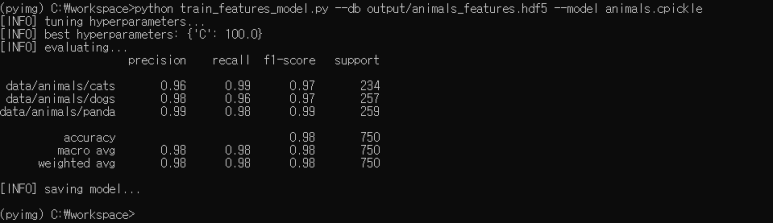
Animals 데이터 세트에서 VGG16 네트워크를 통해 추출 된 기능에 대해 로지스틱 회귀 분류기를 훈련하려면 다음 명령을 실행하면됩니다.
98 %의 분류 정확도에 도달 할 수 있습니다. 이 수치는 10 장의 이전 최고 기록 인 71 %보다 크게 향상되었습니다.
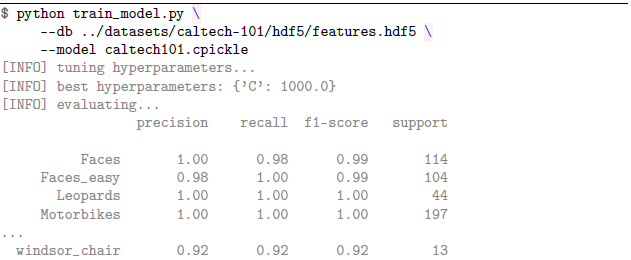
이러한 놀라운 결과는 CALTECH-101 데이터 세트에서도 계속됩니다. 이 명령을 실행하여 CALTECH-101에서 VGG16 피처의 성능을 평가합니다.
이번에는 최소한의 노력으로 101 개의 개별 개체 범주에서 96 %의 분류 정확도를 얻을 수 있습니다!
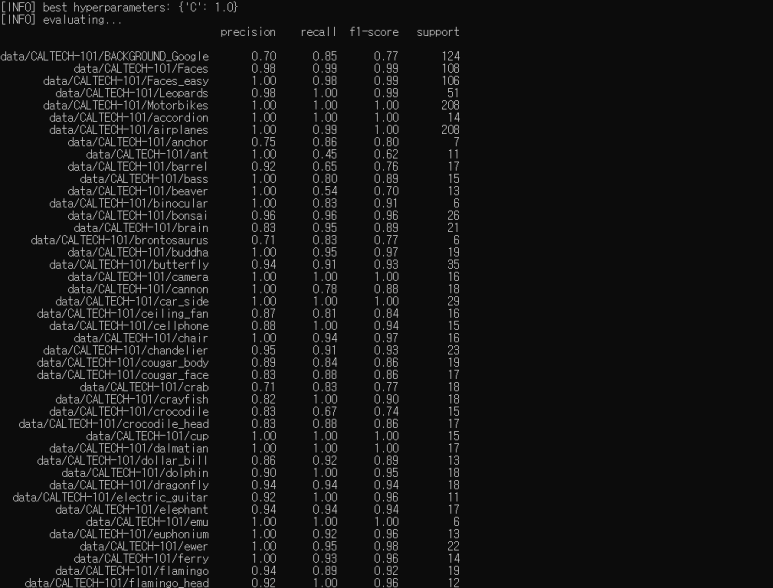
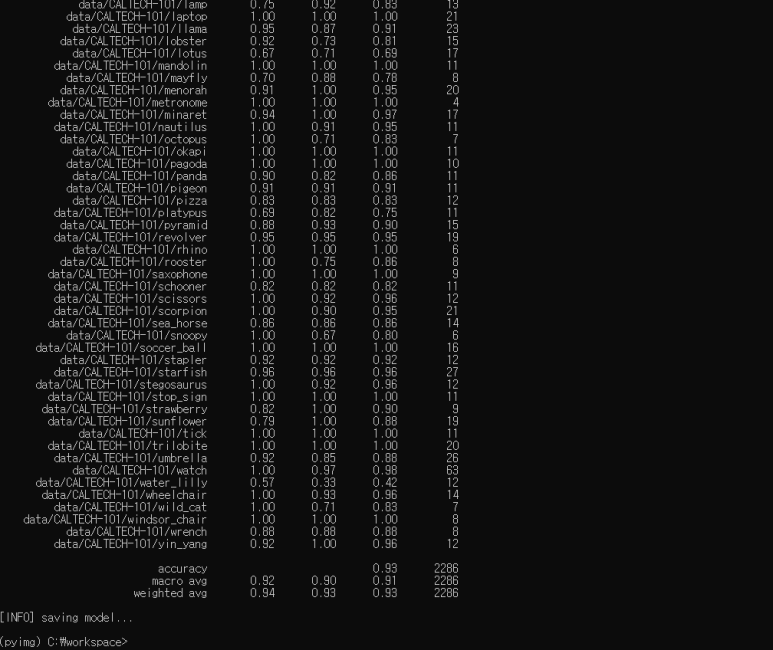
마지막으로, VGG16 기능을 Flowers-17 데이터 세트에 적용 해 보겠습니다. 이전에는 데이터 증가를 사용하더라도 71 %의 정확도를 달성하기 위해 고생했습니다.
이번에는 분류 정확도가 93 %에 도달했습니다. 이는 이전의 71 %보다 훨씬 높습니다. 분명히 VGG와 같은 네트워크는 전이 학습을 수행 할 수 있으며, 고유한 사용자 지정 이미지 분류기를 훈련하는 데 사용할 수 있는 출력 활성화로 식별할 수 있는 피처를 인코딩 할 수 있습니다.
이 장에서는 사전 훈련 된 Convolutional Neural Network를 사용하여 원래 훈련 된 것 이외의 클래스 레이블을 분류하는 개념 인 전이학습을 탐색하기 시작했습니다. 일반적으로 딥 러닝과 컴퓨터 비전에 적용될 때 전이 학습을 수행하는 두 가지 방법이 있습니다.
1. 네트워크를 특징 추출기로 취급하고, 주어진 계층까지 이미지를 순방향 전파 한 다음 이러한 활성화를 가져와 특징 벡터로 취급합니다.
2. 완전히 새로운 완전히 연결된 레이어 집합을 네트워크 헤드에 추가하고 이러한 FC 레이어를 조정하여 새 클래스를 인식하도록하여 네트워크를 미세 조정합니다 (동일한 기본 CONV 필터를 사용하면서).
우리는 VGG, Inception, ResNet과 같은 심층 CNN이 HOG, SIFT, 로컬 이진 패턴와 같이 수작업으로 설계된 알고리즘보다 훨씬 더 강력한 기능 추출 기계 역할을 할 수 있음을 입증하면서 이 장에서 전이 학습의 특징 추출 구성 요소에 집중했습니다. 딥 러닝 및 컨볼 루션 신경망을 사용하여 새로운 문제에 접근 할 때마다 특징 추출을 적용하는 것이 합리적인 정확성을 얻을 수 있는지 항상 고려하십시오. 그렇다면 네트워크 훈련 프로세스를 완전히 건너 뛰어 많은 시간과 노력, 골칫거리를 절약 할 수 있습니다.
다음 장에서는 특성 추출, 미세 조정, 학습과 같은 딥 러닝 기법을 처음부터 적용하는 최적의 경로를 살펴 보겠습니다. 그때까지 전이 학습을 계속 공부하겠습니다.
VGG16을 사용하여 특징을 추출 할 첫 번째 데이터 세트는 “Animals”데이터 세트입니다. 이 데이터 세트는 개, 고양이, 판다의 세 가지 클래스로 구성된 3,000 개의 이미지로 구성됩니다. VGG16을 활용하여 이러한 이미지에서 특징을 추출하려면 다음 명령을 실행하면 됩니다.
Titan X GPU를 사용하여 약 35 초 만에 3,000 개 이미지에서 특징을 추출 할 수있었습니다. 스크립트가 실행 된 후 animals / hdf5 디렉토리를 살펴보면 features.hdf5라는 파일을 찾을 수 있습니다.
Animals 데이터 세트의 .hdf5 파일을 조사하려면 Python 셸을 시작합니다.
HDF5 파일에 features, label_names 및 labels의 세 가지 데이터 세트가 있는지 확인하십시오. 피처 데이터 세트는 실제 추출 된 기능이 저장되는 곳입니다. 다음 명령어를 사용하여이 데이터 세트의 형태를 검사 할 수 있습니다.
.shape가 어떻게 (3000, 25088)인지 확인하십시오.이 결과는 Animals 데이터 세트의 각 이미지 3,000 개가 길이가 25,088 인 특성 벡터를 통해 정량화되었음을 의미합니다 (즉, 최종 POOL 작업 후 VGG16 내부 값). 이 장의 뒷부분에서 이러한 피처에 대해 분류기를 훈련하는 방법에 대해 알아 봅니다.
Animals 데이터 세트에서 특징을 추출한 것처럼 CALTECH-101로도 동일한 작업을 수행 할 수 있습니다.
이제 caltech-101 / hdf5 디렉토리에 features.hdf5라는 파일이 있습니다.
이 파일을 살펴보면 8,677 개의 이미지가 각각 25,088 차원의 특징 벡터로 표현된다는 것을 알 수 있습니다.
Flowers-17에 대한 features.hdf5 파일을 살펴보면 데이터 세트의 각 1,360 개 이미지가 25,088 차원 특징 벡터를 통해 정량화 되었음을 알 수 있습니다.
이제 사전 훈련 된 CNN을 사용하여 소수의 데이터 세트에서 특성을 추출 했으므로 특히 VGG16이 Animals, CALTECH-101 또는 Flowers-17이 아닌 ImageNet에서 훈련 된 경우 이러한 특성이 실제로 얼마나 차별적인지 살펴 보겠습니다.
이제 두 번째로 간단한 선형 모델이 이러한 피처를 사용하여 이미지를 분류 할 때 얼마나 할 수 있는지 추측 해보십시오. 분류 정확도가 60 %보다 낫을까요? 70 %는 비합리적으로 보입니까? 확실히 80 %는 아닐까요? 그리고 90 %의 분류 정확도는 비현실적일까요?
새 파일을 열고 이름을 train_model.py로 지정하고 다음 코드를 삽입합니다.
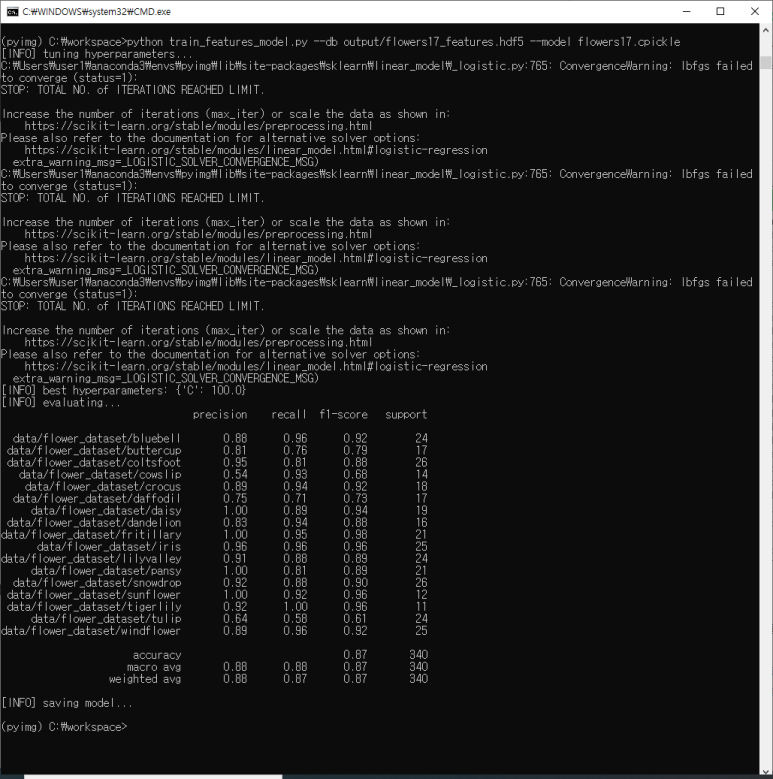
2-7 행은 필수 Python 패키지를 가져옵니다. GridSearchCV 클래스는 매개 변수를 LogisticRegression 분류기로 바꾸는 데 사용됩니다. 학습 후 피클을 사용하여 LogisticRegression 모델을 디스크에 직렬화 합니다. 마지막으로 h5py가 사용되어 HDF5 기능 데이터 세트와 인터페이스 할 수 있습니다. 이제 명령 줄 인수를 구문 분석 할 수 있습니다.
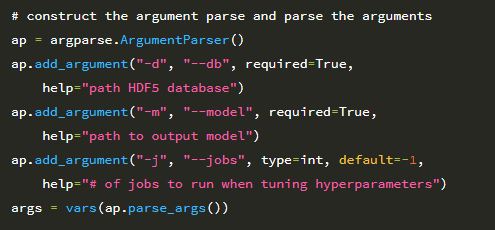
스크립트에는 두 개의 명령 줄 인수가 필요하며 세 번째는 옵션이 필요합니다.
1. –db : 추출 된 기능 및 클래스 레이블이 포함 된 HDF5 데이터 세트의 경로입니다.
2. –model : 여기서 출력 로지스틱 회귀 분류기에 대한 경로를 제공합니다.
3. –jobs : 하이퍼 파라미터를 로지스틱 회귀 모델에 맞게 조정하기 위해 그리드 검색을 실행할 때 동시 작업 수를 지정하는 데 사용되는 선택적 정수입니다.
HDF5 데이터 세트를 열고 학습 / 테스트 분할 위치를 결정하겠습니다.
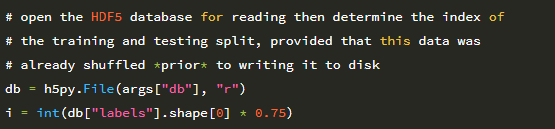
이 장의 앞부분에서 언급했듯이 관련 이미지 / 특징 벡터를 HDF5 데이터 세트에 쓰기 전에 의도적으로 이미지 경로를 섞었습니다. 그 이유는 22와 23행에서 명확 해집니다.
데이터 세트가 너무 커서 메모리에 맞지 않는 경우 , 우리는 훈련 및 테스트 분할을 결정하는 효율적인 방법이 필요합니다. HDF5 데이터 세트에 얼마나 많은 항목이 있는지 알고 있기 때문에 (그리고 우리는 데이터의 75 %를 훈련에 사용하고 25 %를 평가에 사용하고 싶다는 것을 알고 있기 때문에 데이터베이스에 75 % 인덱스 i를 간단히 계산할 수 있습니다. 인덱스 i 이전의 모든 데이터는 훈련 데이터로 간주됩니다. i 이후의 모든 데이터는 데이터를 테스트합니다.
훈련 및 테스트 분할을 고려하여 로지스틱 회귀 분류기를 훈련 해 보겠습니다.
28-31 행은 최적 값이 무엇인지 결정하기 위해 로지스틱 회귀 분류기의 엄격한 매개 변수 C에 대한 그리드 검색을 실행합니다. 로지스틱 회귀에 대한 자세한 검토는 여기 공부 범위를 벗어납니다. 로지스틱 회귀 분류기에 대한 자세한 검토는 Andrew Ng의 노트를 참조하십시오.
array 슬라이스를 통해 훈련 데이터와 훈련 레이블을 어떻게 표시하는지 확인하십시오.
다시 말하지만, 인덱스 i 이전의 모든 데이터는 훈련 세트의 일부입니다. 최상의 하이퍼 파라미터를 찾으면 테스트 데이터에서 분류기를 평가합니다 (36-38 행). 여기에서 테스트 데이터와 테스트 레이블은 배열 슬라이스를 통해 액세스됩니다.
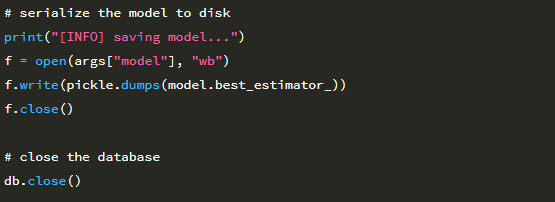
인덱스 i 이후의 모든 것은 테스트 세트의 일부입니다. HDF5 데이터 세트가 디스크에 있고 (메모리에 맞기에는 너무 커서) NumPy 배열 인 것처럼 처리 할 수 있습니다. 이는 HDF5와 h5py를 딥 러닝 및 머신에 함께 사용하는 것의 큰 장점 중 하나입니다. 학습 과제. 마지막으로 LogisticRegression 모델을 디스크에 저장하고 데이터베이스를 닫습니다.
또한 Animals, CALTECH-101 또는 Flowers-17 데이터 세트와 관련된 특정 코드가 있는지 확인해 보십시오. 이미지의 입력 데이터 세트가 위의 33.2에 자세히 설명 된 디렉토리 구조를 준수하는 한 extract_features를 모두 사용할 수 있습니다. extract_feaures.py 및 train_model.py를 사용하여 CNN에서 추출한 기능을 기반으로 강력한 이미지 분류기를 빠르게 구축 할 수 있습니다.